
llm-jpってコミュニティをご存じでしょうか?
llm-jpとは、大規模言語モデル研究開発センターが主宰する研究者のコミュニティ名であり、かつ、日本発LLM開発プロジェクトの名称を指します。前職の会社でGPUについての調査検証をしていたころ、このプロジェクトに参画した人も一定数いたように思います。そのぐらいいろんなところから人が集い、SLM/LLMを作り上げている集団になっています。
すごいモデルがllm-jpから出た!
こちらの提供するモデル、これまでにもたくさんあったんですが、特に今回その目を引くモデルが登場したということで話題になっているモデルが以下です。
これまでリリースされてきたモデルは、LLaMa-3系を使用したものが非常に多いんですが、弱点としてよく上がっていたのが最大コンテキスト長の短さでした。例えばこれの前のバージョンである llm-jp-3.1-8x13b-32K などでは、最大コンテキスト長が32kトークンしかなく、最近のSLM/LLMの使い方としてはちょっと収まらないと敬遠されてしまうケースも多かったのです。
また、このころすでにReasoningモデルも多く登場する中、このモデルは非Reasoningモデルであり、その性能がどうしても大きく米国や中国、欧州モデルに引き離されていたという厳しい現実もありました。
最大コンテキストサイズ:64kトークン
一番の目玉は最大コンテキスト長が64kまで拡張されたことです。この64kというトークン量はまさにちょうどいい極みの位置で、他のモデルでもレスポンスの速度・知識として格納する量ともにバランスの良い位置づけであり、32kでは対応しきれてなかったかなりのタスク量がこなせるものと予想されます。
また、Reasoningにも対応しており、従来のモデルと飛躍するレベルで回答の精度を引き上げることができているようです。日本語特化モデルでここまでしっかりできているモデルはそうそうありませんで、しかも事前学習から日本の機関が作り上げてるオープンウェイトでやってるのはこれとPreferred Networksさんぐらいなものではないでしょうか。クローズだともっと多いんだろうなぁ。
4段階の学習プロセス
llm-jp-4モデル群は以下のような4段階の学習フェーズを経ており、会話などの情報は事前学習の先に実行し、その後数学的・長文コードといった情報を学習させる工程を踏んでいるようです。
通常では、事前学習・事後学習という2つの大きなまとまりをもって学習をしますが、今回のこのモデルではその間に「中間学習」というものを行っています。64kコンテキスト長をサポートするであろう部分はこのあたりで鍛えられてるようです。
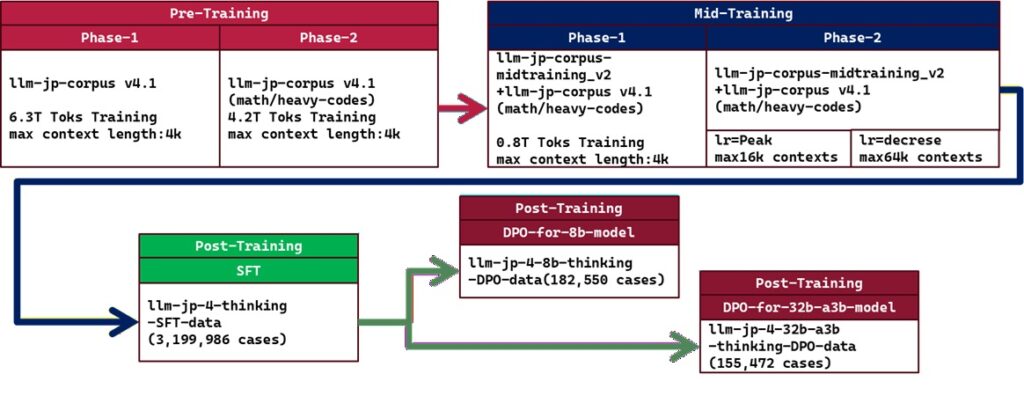
学習時、そのlearningレートは初期段階で0からwarmupを行い、ピーク値に持って行ったあと、そのピーク値を維持しながら学習を進めていきます。終盤に学習率を0に降下させながら処理を継続していくのですが、この中間処理時点の終盤、学習率を落とす段階で最大コンテキスト長64kトークンの学習ケースを処理していくようになっていました。
その後、SFTにてInstruction能力の付与、DPOにてアライメントを実行し、最終的にモデルとしてリリースされます。DPOの段階のデータを拝見させていただきましたが、以下の構造をとってました。
| 項目 | 概要 |
|---|---|
| messages | 質問を含めた入力データ(マルチターンの場合は質問する直前の一連のターンを含む) |
| chosen_analysis | Reasoning中の内容のうち、質問に対して選択すべき内容を記載、英語で記述 |
| reject_analysis | Reasoning中の内容のうち、質問に対して選択してはいけない内容を記載、英語で記述 |
| chosen_final | 最終回答内容のうち、質問に対して選択すべき内容を記載、日本語で記述 |
| reject_final | 最終回答内容のうち、質問に対して選択してはいけない内容を記載、日本語で記述 |
英語でのReasoningはモデルアーキテクチャとも相性が良いと考えられ、それゆえに英語表記のままなのかな?と推察しました。
llm-jp-4-8b-Thinkingというモデル
そんな llm-jp-4シリーズの中で私が目を引いたのは llm-jp-4-8b-Thinking というモデルです。所謂SLMと言われるDenseモデルです。構造は以下の通りで、そのベースはLLaMa-2(LlamaForCausalLM)が使われてるようです。
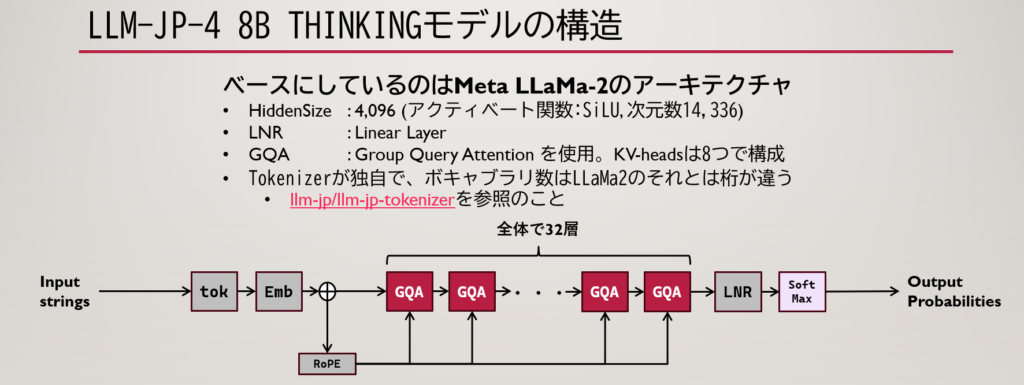
これはどちらかというと現在のSLM/LLMの源流と言ってもいいぐらいの構造をしていて、Positional Encodingの進化系であるRoPE、MultiHead Attentionの進化形であるGroup Query Attentionを採用しています。FFNは通常のDense構成と変わりなく、そのアクティベート関数はSiLUを使用しています。
次元数の扱いは元のオリジナルと比べると高めに設定されており、通常の隠れ総次元数は4096次元、FFNを通る際には14,336次元まで拡張されます。
なお、もう一つのモデルである32B-A3Bモデルは、Qwen3のアーキテクチャを採用しています。
それぞれのモデルでそれぞれ異なるアーキテクチャを用いて作り上げてるところに、また変わったものを感じています。
独自のトークナイザ:llm-jp4 tokenizer
トークナイザはllm-jp-4ならではの独自路線というか、フルカスタマイズされた構成をとっています。カスタマイズモデルなのでベースはあり、それ自体はLlamaFastTokenizerの流れを踏んでます。しかし、そのメッセージパーサーが特殊で、OpenAIのHarmonyを用いています。
このあたりは詳しくは https://huggingface.co/llm-jp/llm-jp-4-8b-thinking/blob/main/llmjp4_tokenizer.py を見るとわかりやすいかと思います。
メッセージパーサーはいわゆる字句解析エンジンを指しており、これを従来のLlamaTokenizerと異なるものを使ってるのを見るのは初めてかもです。詳しいところはもっと深堀しないとわからないですが、少なくともそこにここ最近の技術を取り込むことで、より効率の良いトークナイザとしての挙動やトークンの定義が行われているものと推察しています。
それゆえにモデルのVocab数も大きく差があり、196,608もあります。従来のLLaMa2-7b-itが32,768ですので、大きくこのあたりは拡張されたものと考えられます。また、LLaMa-2はBPEというアルゴリズムでくみ上げられたTokenizerであるのに対して、llm-jp4のそれはUnigram Tokenizerと呼ばれ、日本語ならではの適合しやすさを持ったちょっと変わったTokenizerです。
これについて、私自身気になっていろいろ調べた内容がありますので、それは今後の記事の中で記述したいと思います。実はTokenizerってLLMのアーキテクチャ以上に重要な意味を持つ代物であることをここにきてようやく頭が理解してくれました・・・のであります!
llm-jp4モデルの意義
llm-jp4モデルの登場は非常に意義が大きく、これまで登場してきたクローズドモデルとは異なり、広くユーザに使われる国産モデルが登場したことを意味します。しかも決して他のモデルから大きく見劣りするものではなく、実務的に利用可能なレベルということで、改めて言うんですが、このモデルの登場は非常に大きいです。
確かに新技術はそこにありません。しかし、普通では得られない独自に構築したデータセットをもってその内訳も公開しつつ学習させ、リリースしたことにより、多くのAI技術者がこれを参考することになるのかなと思いますし、その発展形として、単なるファインチューニングではないものの、その中に少し新しい取り組みを加えながら進化させていくその姿は、他国のモデルではあんまり見かけない内容だなぁと感じています。
日本の言語体系は世界的にはなかなか独特なところもあり、そういう意味でもそこに特化させるべく適合させたということで、今後の日本におけるソブリンAIとしての位置づけがどのモデルに該当していくのか、というところはまさに楽しみなネタとして追いかけていきたくなる話ではないかと思っています。
がんばれニッポン!これに尽きるのかなぁ。

コメント