ガチでスクラッチから作ってみたいそんなあなたに
今、X.com上でこんなリポジトリが盛り上がってます。これ、何が入ってるかと言いますと、スクラッチでTransformerを使用したLLMを事前学習から始めるためのキットが詰まっています。全体構成全体構成は以下のようになっています。trai...

 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence 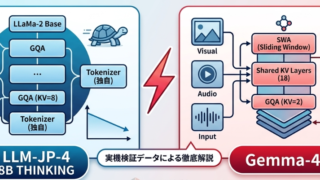 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence Artificial Intelligence
Artificial Intelligence Artificial Intelligence 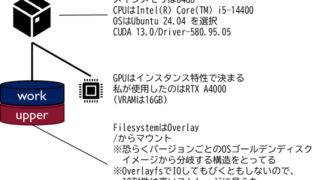 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence