

先の投稿でKVキャッシュの容量について話題を出したので、これを掘り下げて解説することにしました。
トランスフォーマー型LLM/SLMにおける基本的な動き
基本的にこの手のLLM/SLMはこんな動きをしてる。
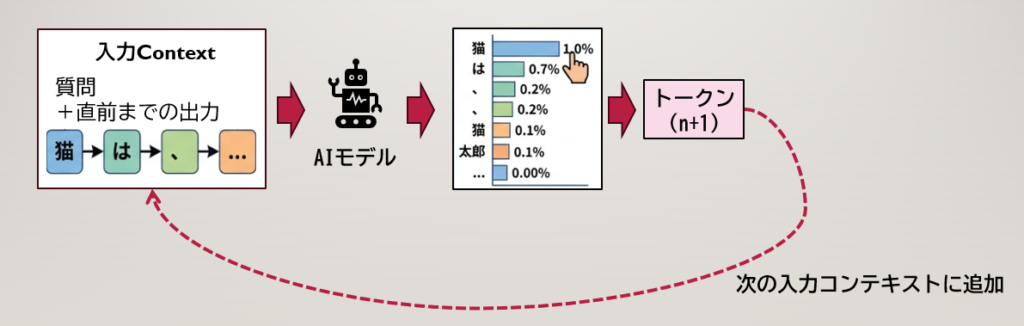
AIモデルは、特にBi-Directionalと呼ばれるモデルを使うとよくわかるのだけど、「ステートレスな型変換器」みたいな動きをするんです。LLM/SLMではこれが「テキスト→テキスト」に変換されてるだけなんですが、突き詰めまくったらまさに「人工知能だ・・・」みたいになって盛り上がってるわけで。
実態としては、そこでは何かを保存するという動きをせずに、ただひたすらAI自体は「次の言葉を予想する」という動きをしています。しかも一言だけ。1単語だったり1文字の場合もあるでしょう。でもやってることは
「文章の断片の次の予測」です。
この時、原理的な動きで言えば、都度次のトークンを読み出すために、「直前までの出力を含めた会話履歴全体」を放り込むのって効率的と言えるでしょうか?というところで、現実的な観点に戻してみてみると、ぶっちゃけ「できないことはないけどめっちゃ遅い」ということになります。
そこで編み出されたのがKVキャッシュです。
KVキャッシュとは
つまり、KVキャッシュとは、推論における「出力直前までの全データのAttention層における、Key/Valueデータを一時保管する領域」なんです。
なぜキャッシュできるかというと「直前までの出力」は「すでに確定済みのデータ」であるからです。
原理的な説明の場合、直前の出力状態まですべてニューラルネットワークに取り込み、そこまでの状態を再計算させてその直前の状態を確立しなおさなければなりません。これは、AIの仕組み上におけるステートレス性によるところにあります。
しかし、確定した状態までの情報をわざわざ計算で求めるには、あまりにもその導出のための計算量が大きすぎるのです。
そこで、直前の状態までを計算した状態のAttention層におけるKey/Value値をキャッシュすることにした、それがKVキャッシュです。
なぜFFNの出力をキャッシュしないのか
情報をKVに限った理由は「Attentionの計算が最も比重が高いから」です。そしてFFNを通過した情報は「再現性がない」ためです。
Attentionは本来前トークンのKey/Value値をもって計算する処理ですが、その計算オーダーは “O((n^2)d)” です。nは系列長、dは次元数を指します。となると、nが長くなればなるほど計算量は増えていくことになります。
これに対してFFNは次元を一定量の拡張してアクティベーション関数に通して非線形化し、そして元の時点に閉じるという「あらかじめ決められた関数を通過するだけ」の処理をします。その場合の計算オーダーは
“O(n)”となり、計算オーダー的にはAttentionのほうが圧倒的に多いんです。Attention層の再現にかかるコストを考慮すると、FFN出力情報の再現は本当に小さな計算量で事足りるということにもなります。
Attention層は文章構造を構築する際に使われます。この構造は場合によってはその後の局面でも有効に再利用することが可能になります。そのうえでFFN層を外すことで余計な計算過程データをキャッシュせずに済み、必要なメモリ量も削減ができます。結果としてキャッシュすべきデータの対象が定まっていったようです。
KVキャッシュの量子化
KVキャッシュはGPUで駆動する場合、GPU上のVRAMに確保されます。
これをケチりたい・・・・(失礼)という人も多いと思います。もちろんこれらのデータはテンソルなので、データのよう措置の制度を落とすことでその消費量を削減することが可能です。これをKVキャッシュの量子化と言われています。
モデルの重みデータの場合は、だいたい4bitぐらいがボーダーラインになることが多く、量子化に強いモデルであれば2bitや3bitのケースもありますが、経験上4bitをボーダーラインにすることが多いです。
キャッシュはちょっと様相が異なり
- 8-bitまでは比較的安全圏
- 4-bitは要検証圏
- 2-bit以下は危険圏
と言われています。これはモデルの適正によって大きく結果が分かれるといわれています。昔のモデルが登場してた頃から8bitは多く検証されてることが多く、その毀損率もかなり小さいというのはもはや定説レベルになっていますが、4bitは場合によってはヒットしなくなることもあり、要注意と言われていました。
このあたりの影響はパフォーマンスとして跳ね返ってくることが多く、要は「直前までの情報をどこまできちんと再現できるか」にかかってきます。出力が遅くなる場合もあれば、最悪のケースだと同じトークンを延々繰り返すというような悪影響になって表れるケースもあります。
基本
- 8bitまではとりあえずOK、4bitまで落とすなら一度検証しようね
ということで認識すればいいのかなと思います。
こういうチューニングはAPI型モデルでは考慮することがほとんどありません。しかしながら、推論の過程は押さえておいて損はないかなと思いますので是非覚えてもらったほうがいいんじゃなかろうかと思います。
AIはね、思った以上にメモリ食うんですよ(´Д`)ハァ…

コメント