
ローカルLLMを動かすときの重要なカギ:メモリ帯域
ローカルLLMやSLMを使用するとき、皆さんはどういうグラフィックボードを使用されるのでしょう?
大体は安価な製品なちょい古めの・・そう、例えばRTX3060-12GBみたいなものを使って動かしたりすることは結構あったんじゃないかって気がします。
企業でも簡易評価をするレベルとなると、そのあたりのレベルのGPUを使って評価し、本格的なところに至るあたりでちゃんとしたグラフィックボードを構えて推論基盤を構成することもあるようで。
そんな中、最近ですとDGX-Sparkという機種が登場しました。こちらはメインプロセッサこそARMですが、グラフィックプロセッサにNVIDIA Blackwell GB10というユニファイドメモリと連携させた省電力型のGPUが搭載され、128GBという広大なメモリ空間を一定割合に区切って使用することを可能としています。
80GBものVRAMを切り出すことも不可能ではなく、それはNVIDIA A100と同等のレベルのVRAMを用いる環境だということでだいぶ脚光も浴びたのではないかと。だって、600万円ぐらいするようなものがわずか60-100万円程度で手に入るわけですので。かなりこれを購入した人もいらっしゃるでしょう。
しかし現実はそう甘くはありません。実際に動かした人の第一印象は大体が「動くが遅い」だったはずです。もともとGB10自体がGPUというよりはNPUという位置づけにあり、8bit/4bitという低精度演算に強いことも挙げられますが、それ以上に大きな要因になったのは「メモリ帯域」です。今回はこのメモリ帯域に焦点を当てて説明できたらと思います。
例えばそのハード、メモリ帯域はいくら?
DGX-Sparkは、そのユニファイドメモリ(CPU側にもGPU側にも利用できる適応幅の広いメモリ)の帯域として273GB/sという最大帯域が割り当てられます。
あれ?なんか単位おかしくない?という人もいるかもしれませんが、おかしくありません。メモリ帯域、実はグラフィックプロセッサに用いられるメモリの帯域は、一般的なものでもCPUに適用されるメモリのおよそ10倍程度はあることが多いです。前述したGeForce RTX 3060-12Gの場合、そのメモリ帯域はおよそ360GB/sです。
なお、DDR5メモリとかですと、その帯域はおよそシングルチャネルで38.4GB/s、デュアルチャネルで70GB/sと言われています。ユニファイドメモリがGPU用にも適用できるといっても、その限界は高かったり低かったりもします。では、以下に主だったNPU/GPUの帯域を一覧化してみましたのでご参考まで。
GPU/NPUの帯域
| クラス | 製品名 | メモリ帯域 |
|---|---|---|
| 1.8TB/sクラス | RTX PRO 6000 Blackwell | 1792 GB/s |
| RTX 5090 | 1792 GB/s | |
| 800-1000GB/sクラス | RTX 600 Ada Generation | 960 GB/s |
| Mac Studio M3 Ultra | 819 GB/s | |
| 450~650GB/sクラス | Mac Studio M4 Max | 546 GB/s |
| MacBook Pro M5 Max | 460~614 GB/s | |
| AMD Radeon AI PRO R9700 | 640 GB/s | |
| Tenstorrent Blackhole p150 | 512 GB/s | |
| RTX A4000 | 446 GB/s | |
| 250~300GB/s (Unifiedメモリ)クラス |
DGX Spark | 273 GB/s |
| Mac mini M4 Pro | 273 GB/s | |
| Ryzen AI Max / Strix Halo | 256 GB/s | |
| 薄型軽量AI PCクラス | MacBook Air M5 | 153 GB/s |
| Snapdragon X Elite | 135 GB/s | |
| Intel Lunar Lake | 136 GB/s | |
| Snapdragon X2 Elite | 152~228 GB/s | |
| CPU用メモリ:例 DDR5-4800の場合 |
Single Channel | 38.4 GB/s |
| Dual Channel | 70 GB/s |
こうしてみればわかるかと思うのですが、メインCPU向けに使われるメモリとGPU向けに使用されるビデオメモリとではこれだけの開きがあります。
なぜそこまで高速な処理が求められるか?
なぜこれほどの開きになるのかというと、グラフィックプロセッサ自体に求められる性能要件によるところが非常に大きいと考えられます。
そもそもグラフィックプロセッサとは何をするものでしょうか?AIを動かすものではありません。あくまで「画像を表示するためのもの」です。広大なディスプレイに対して、1つ1つの画素に対して「極力同時にずれなくある時点の画像を表示させる」という使命があります。これはオフィス用途のものよりも、特に3D表示を要求するようなゲーム用のプロセッサに対して強く要求されます。
例えば、画像が途中でずれが生じて上半分とした半分の時系列がずれるような状況下で、リアルタイムなアクションゲームを操作していたらゲームをしている人の立場から見るとどうなるでしょう?明らかにパニックを起こすはずです。昨今人気のゲームはそうしたバーチャルリアリティを重視して作られたものが多く、身体感覚とゲーム内のキャラクターの動作をうまくシンクロさせる必要が出てくるため、こうした要件は必須要件になります。
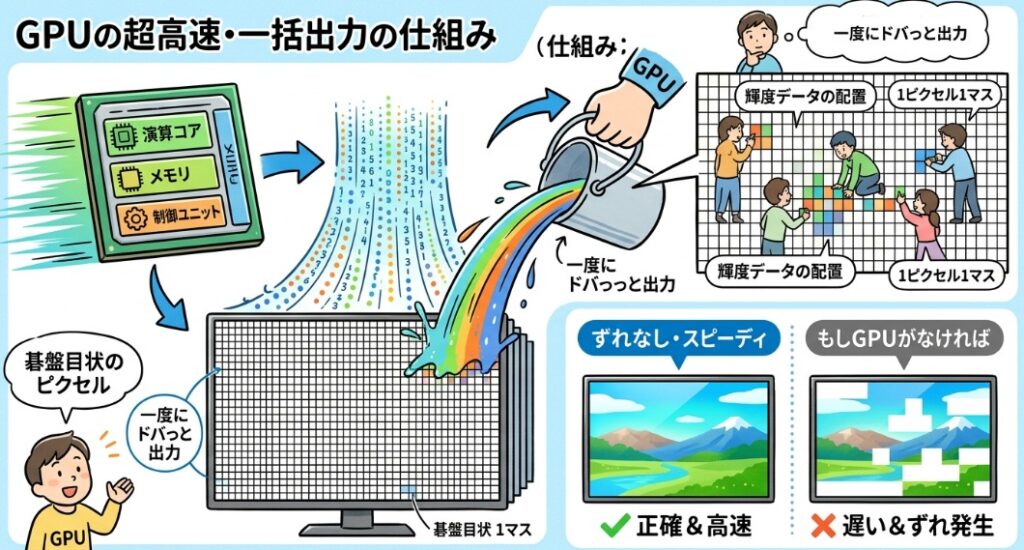
となりますと、広大な画面、それはディスプレイの画面を非常に細かい碁盤目状に組まれたところへ、1つ1つ輝度(という名の数値)を一度にドバっと出力する必要があります。それも同時に。こうしたときに必要になるのが以下の2点なのです。
- 驚異的ともいえる並列計算処理能力
- その驚異的な計算能力についていくだけの広大かつ広帯域なビデオメモリ
そのため、もともとGPUは並列計算能力と高速なメモリIOを有した形で作られていました。
NVIDIAはその特性とDeepLearningの計算特性がマッチすることを認識し、CUDAライブラリを開発し、これをDeepLearning「にも」適用したというのが大いなるきっかけになったわけです。今日のAIは、これなくしては語れません。
VRAMは大変お高い・・・(´Д`)ハァ…
ただ、VRAMは大変お高い存在でもあります。それは、メインメモリよりもメモリ帯域が広いからです。バスのベースクロックはメインメモリとあまり変わりありませんが、そのぶん、1クロックで運ぶデータ量が非常に多くなっており、その分作るメモリ素子の構築レベルも非常にレベルが高いものになっています。そのため、同じ要領でも天と地ほど離れるぐらいに金額差があるのが特徴でもあります。
さらにこれをはるかに上回るHBMというメモリモジュールがあります。これは、DRAMチップを縦方向に重層的に積み上げたメモリモジュールで、メモリ集積率がDDRやGDDRよりもはるかに多く、加えてその重層メモリ空間内のデータのやり取りを実現するためにメモリモジュール間に穴を通すという、なんとも想像を絶する芸当を製造工程の中に組み込んでいるのがコスト高の要因となってます。
(その複雑さと相まって、熱対策面・テストレベルの高さなどもコストに乗っかっていきます)
これらはNVIDIAですとB100/200, H100/200といったハイエンドGPUで使用されることが多いです。そのビット幅はGDDRとも桁が違う4096bit x2という想像を絶する構造で、最大帯域幅はこれも桁違いの4.09TB/sです。(NVIDIA B300の場合:https://www.techpowerup.com/gpu-specs/b300.c4375 より引用)こうしたメモリを搭載したGPUは、主にビッグテックと言われているベンダーの学習基盤に採用されることが多いです。
Unifiedメモリ:廉価なVRAMであり、高価なメインメモリ
その点UnifiedメモリはちょうどメインメモリとVRAMの中間に位置するようなメモリ素子であり、VRAMほど高速ではないですが、メインメモリよりは高速であるような特性を持っています。これをGPUとVRAMが対応するかのように配置してはんだ付けすることで、GPUに近い動かし方をしても「そこそこ高速に」動かせるようにしています。
メインメモリとVRAMの比率は、BIOSでの設定に任せるか、ソフトウェアで制御するかを選べるようになっていることが多く、通常だと何百万円も必要となりそうなGPUが欲しくなるところを比較的安価(30-70万円ぐらい)で買えるようにしています。特に目立つのはNVIDIAではDGX-Spark、AMDではRyzen AI MAXじゃないでしょうか。
これらを使用することで確かに大きなモデルを動かすことは可能ですが、完全なGPUと比べて計算素子数が少ない上、UnifiedメモリではVRAMほどのスピードがでないてんにはやっぱり気を付ける必要があります。DGX-Sparkですら273GB/sしかなく、今となっては型遅れのRTX 3060にすら届かない速度であるため、そのまま動かそうとするとびっくりするほど遅くて涙が出てしまうと思います。
こういう場合の対策としては以下の点が挙げられます。
- 推論用途を前提とすること
あくまで、AIに推論をさせる用途に限定しましょう。学習処理は、GPUの機能・性能をフルに要求し、その発熱量も尋常ではなくなります。推論の場合は、推論用計算回路しか使わないため、発熱も一定量に押さえられ、それでいてそれなりの速度で推論をしてくれます。 - 量子化しましょう
量子化とは、行列データの1つ1つの計算精度を落とす手法で、これによってメモリ必要量だけでなく計算処理精度も低減でき、より高速に結果を出力することが可能になります。それでいて、量子化=画像に例えると色数を落とす手法に例えられるのですが、結果として出力される内容の誤差が比較的小さく済むといわれており、そのモデルの性能を大きく損ねることはありません。
Unifiedメモリを搭載した機種自体、そうした量子化を前提として動かしているため、必ずこれは適用(適用すべき量子化モードはプロセッサの計算能力次第で決まる)するようにしてください。 - どのサイズのモデルに適切かを見極めてください
昨今、AIモデルの性能は単純にパラメータ数では測れないぐらいに学習方式やデータセットが充実したことで、格段に向上してきており、今や4Bモデルで以前一世を風靡したGPT-4の性能に迫ることができるようになってきました。
大きなモデルを動かす必要性があるかどうか、小さなモデルでどこまで担保できるかどうかを見極め、適切なモデルで動かすことをお勧めします。
より身近になるローカルLLM/SLM
こうした廉価なデバイスも登場することで、インターネットにべったり頼るAPI型のリッチなAIモデルの代替策としてこうしたローカルLLM/SLMも多くの人が触れられる領域に徐々になってきました。こうしたAIモデルの性能向上は、私も当初予測ができておらず、AIの仕組みを知るころには「今まで知ったこと必要ないんじゃない?」と感じるようになるほど、いろいろな常識的だったことが塗り替えられ続けています。
API型のモデルに頼るのもいいでしょう、やっぱり性能は今でも段違いです。しかし、昨今世界のいろんなところで戦争は起きてますし、所謂他国からひっそりと何らかの攻撃をされることも増えてきたといわれることだってありますし、そうした対策の一環として、例えば国内企業の中でもっとAIエンジンを増やして国内トラフィックの中でAIが使えるようにする、エッジデバイスで基本的な推論はできるようにしとくと言ったようなことが必要になってくるのではないかと個人的には感じています。
そのうち一家に一台プチAIがかわいくいろいろ世話してくれる社会、そんなのがあってもいいんじゃないかと。先の読めない世の中にいますが、もっと前を向いていろいろな方向を見据え、私も行動したいと思っています。
コメント