

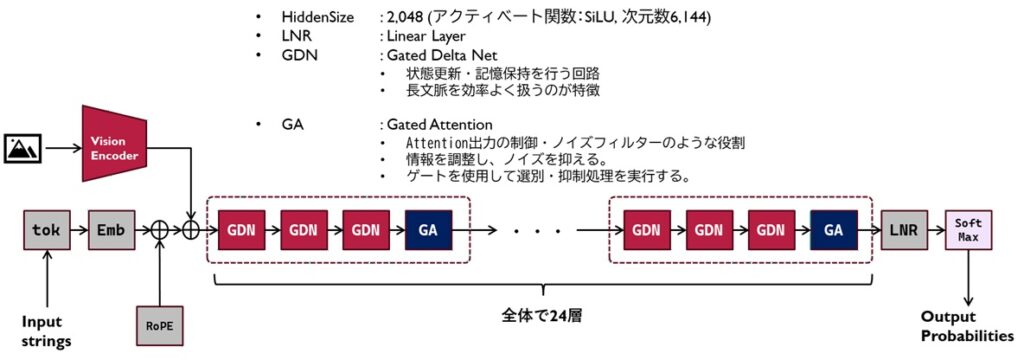
再掲:Qwen3.5-Denseモデルを例に
以下は、Qwen3.5モデルの1例をとってその構造を描いてみたのですが、実際のところどういう風にソースなどでは表現されているのでしょうか?
ソースで見たい場合は以下のリポジトリを参照すればよいかと思います。
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_5/modular_qwen3_5.py
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_5/modeling_qwen3_5.py
modular_qwen3_5.pyは全体構造を示し、modeling_qwen3_5.pyはその1つ1つの構造をブレイクダウンしたような感じになっています。
こうしたモデル構造は、以前はモデルを作成したメーカーのリポジトリに格納されていることが多かった(Gemma1とかWhisperとかはオリジナルのソースがGoogle DeepmindやOpenAIのリポジトリに格納されていたりします)のですが、現在はHuggingfaceがこのあたりを掌握しており、メジャーどころのモデル構造はだいたいtransformersライブラリが押さえています。
Qwen3.5も現在は盛んにファインチューニングがなされており、そのアーキテクチャもこのような形できちんと収録されているというわけです。どこにも見合うモデルがない場合は、そのモデルのconfig.jsonを参照し、どのアーキテクチャを使用しているかについて確認してみるといいかなと思います。
本来は、重みづけデータがリポジトリに保存されていることが基本であり、その拡張子は .safetensors で保存されています。これはあくまで数値データの塊に過ぎず、これを構成するにはtransformersのようなライブラリを使用してモデルの概形をくみ上げていく必要があります。この操作はGGUFなどでモデル構造もまとめて規定フォーマットに詰め込むことをしない限り、回避不可避の操作になるため、このような構造を示すソースは絶対どこかから入手しなければならないのです。
機構のソース内容を覗く
Attention機構を例にとりましょう。Qwen3.5はGDNとGAを3:1で混合して1セットにした層を2Bモデルでは4層、つまり全体で24層の構造を組み合わせたものになります。
Gated Delta Networkの実装
では、Qwen3.5では2種類のAttention層を構成していますが、その片方、Gated Delta networkを見てみます。
これは、クラスとして Qwen3_5GatedDeltaNetにてもたらされます。
基本構造として、クラスであるため__init__ と、関数 forward が必須要素として乗っかります。
__init__ はクラスが作成された場合のその内部変数に関して定義されますし、 forward 関数は次のステップに移るまでに最低限実行しなければならないことが記述されています。
処理の流れを見るには、この2つの関数について調べることが必須事項となります。
class Qwen3_5GatedDeltaNet(nn.Module):
def __init__(self, config: Qwen3_5Config, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.num_v_heads = config.linear_num_value_heads
self.num_k_heads = config.linear_num_key_heads
self.head_k_dim = config.linear_key_head_dim
self.head_v_dim = config.linear_value_head_dim
self.key_dim = self.head_k_dim * self.num_k_heads
self.value_dim = self.head_v_dim * self.num_v_heads
self.conv_kernel_size = config.linear_conv_kernel_dim
self.layer_idx = layer_idx
self.activation = config.hidden_act
self.act = ACT2FN[config.hidden_act]
self.layer_norm_epsilon = config.rms_norm_eps
# QKV
self.conv_dim = self.key_dim * 2 + self.value_dim
self.conv1d = nn.Conv1d(
in_channels=self.conv_dim,
out_channels=self.conv_dim,
bias=False,
kernel_size=self.conv_kernel_size,
groups=self.conv_dim,
padding=self.conv_kernel_size - 1,
)
# time step projection (discretization)
# instantiate once and copy inv_dt in init_weights of PretrainedModel
self.dt_bias = nn.Parameter(torch.ones(self.num_v_heads))
A = torch.empty(self.num_v_heads).uniform_(0, 16)
self.A_log = nn.Parameter(torch.log(A))
self.norm = (
Qwen3_5RMSNormGated(self.head_v_dim, eps=self.layer_norm_epsilon)
if FusedRMSNormGated is None
else FusedRMSNormGated(
self.head_v_dim,
eps=self.layer_norm_epsilon,
activation=self.activation,
device=torch.cuda.current_device(),
dtype=config.dtype if config.dtype is not None else torch.get_default_dtype(),
)
)
self.out_proj = nn.Linear(self.value_dim, self.hidden_size, bias=False)
self.causal_conv1d_fn = causal_conv1d_fn
self.causal_conv1d_update = causal_conv1d_update or torch_causal_conv1d_update
self.chunk_gated_delta_rule = chunk_gated_delta_rule or torch_chunk_gated_delta_rule
self.recurrent_gated_delta_rule = fused_recurrent_gated_delta_rule or torch_recurrent_gated_delta_rule
if not is_fast_path_available:
logger.warning_once(
"The fast path is not available because one of the required library is not installed. Falling back to "
"torch implementation. To install follow https://github.com/fla-org/flash-linear-attention#installation and"
" https://github.com/Dao-AILab/causal-conv1d"
)
self.in_proj_qkv = nn.Linear(self.hidden_size, self.key_dim * 2 + self.value_dim, bias=False)
self.in_proj_z = nn.Linear(self.hidden_size, self.value_dim, bias=False)
self.in_proj_b = nn.Linear(self.hidden_size, self.num_v_heads, bias=False)
self.in_proj_a = nn.Linear(self.hidden_size, self.num_v_heads, bias=False)
def forward(
self,
hidden_states: torch.Tensor,
cache_params: Cache | None = None,
attention_mask: torch.Tensor | None = None,
):
hidden_states = apply_mask_to_padding_states(hidden_states, attention_mask)
# Set up dimensions for reshapes later
batch_size, seq_len, _ = hidden_states.shape
use_precomputed_states = (
cache_params is not None and cache_params.has_previous_state(self.layer_idx) and seq_len == 1
)
# getting projected states from cache if it exists
if use_precomputed_states:
conv_state = cache_params.layers[self.layer_idx].conv_states
recurrent_state = cache_params.layers[self.layer_idx].recurrent_states
mixed_qkv = self.in_proj_qkv(hidden_states)
mixed_qkv = mixed_qkv.transpose(1, 2)
z = self.in_proj_z(hidden_states)
z = z.reshape(batch_size, seq_len, -1, self.head_v_dim)
b = self.in_proj_b(hidden_states)
a = self.in_proj_a(hidden_states)
if use_precomputed_states:
# 2. Convolution sequence transformation
# NOTE: the conv state is updated in `causal_conv1d_update`
mixed_qkv = self.causal_conv1d_update(
mixed_qkv,
conv_state,
self.conv1d.weight.squeeze(1),
self.conv1d.bias,
self.activation,
)
else:
if cache_params is not None:
conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))
conv_state = cache_params.update_conv_state(conv_state, self.layer_idx)
if self.causal_conv1d_fn is not None:
mixed_qkv = self.causal_conv1d_fn(
x=mixed_qkv,
weight=self.conv1d.weight.squeeze(1),
bias=self.conv1d.bias,
activation=self.activation,
seq_idx=None,
)
else:
mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :seq_len])
mixed_qkv = mixed_qkv.transpose(1, 2)
query, key, value = torch.split(
mixed_qkv,
[
self.key_dim,
self.key_dim,
self.value_dim,
],
dim=-1,
)
query = query.reshape(batch_size, seq_len, -1, self.head_k_dim)
key = key.reshape(batch_size, seq_len, -1, self.head_k_dim)
value = value.reshape(batch_size, seq_len, -1, self.head_v_dim)
beta = b.sigmoid()
# If the model is loaded in fp16, without the .float() here, A might be -inf
g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias)
if self.num_v_heads // self.num_k_heads > 1:
query = query.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
key = key.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
if not use_precomputed_states:
core_attn_out, last_recurrent_state = self.chunk_gated_delta_rule(
query,
key,
value,
g=g,
beta=beta,
initial_state=None,
output_final_state=cache_params is not None,
use_qk_l2norm_in_kernel=True,
)
else:
core_attn_out, last_recurrent_state = self.recurrent_gated_delta_rule(
query,
key,
value,
g=g,
beta=beta,
initial_state=recurrent_state,
output_final_state=cache_params is not None,
use_qk_l2norm_in_kernel=True,
)
# Update cache
if cache_params is not None:
cache_params.update_recurrent_state(last_recurrent_state, self.layer_idx)
# reshape input data into 2D tensor
core_attn_out = core_attn_out.reshape(-1, self.head_v_dim)
z = z.reshape(-1, self.head_v_dim)
core_attn_out = self.norm(core_attn_out, z)
core_attn_out = core_attn_out.reshape(batch_size, seq_len, -1)
output = self.out_proj(core_attn_out)
return output
変数一覧
内部使用する変数は以下の通りです。
| 変数名 | 説明・内容 |
|---|---|
| self.hidden_size | モデルの隠れ層のサイズ |
| self.num_v_heads | 値ヘッドの数 |
| self.num_k_heads | キーヘッドの数 |
| self.head_k_dim | キーヘッドの次元数 |
| self.head_v_dim | 値ヘッドの次元数 |
| self.key_dim | 全キーヘッドの合計次元数 |
| self.value_dim | 全値ヘッドの合計次元数 |
| self.conv_kernel_size | 畳み込み(Conv1d)のカーネルサイズ |
| self.layer_idx | 現在のレイヤーインデックス |
| self.activation | 活性化関数の名称 |
| self.act | 活性化関数の実装 |
| self.layer_norm_epsilon | RMS Normのイプシロン値 |
| self.conv_dim | 畳み込み層の入出力チャンネル数(Q, K, Vの合計) |
| self.conv1d | Conv1d層のインスタンス |
| self.dt_bias | タイムステップ用バイアスパラメータ |
| self.A_log | 対数化されたA行列パラメータ |
| self.norm | 正規化層(RMSNormGated)のインスタンス |
| self.out_proj | 出力投影用のLinear層 |
| self.causal_conv1d_fn | 因果的畳み込み処理関数 |
| self.causal_conv1d_update | 因果的畳み込みの更新用関数 |
| self.chunk_gated_delta_rule | チャンクベースのデルタルール処理関数 |
| self.recurrent_gated_delta_rule | 再帰的なデルタルール処理関数 |
| self.in_proj_qkv | QKV投影用のLinear層 |
| self.in_proj_z | Z投影用のLinear層 |
| self.in_proj_b | B投影用のLinear層 |
| self.in_proj_a | A投影用のLinear層 |
forward関数のフロー
の処理は大きく分けて「準備」「畳み込み」「アテンション(デルタルール)」「出力」の4つのフェーズで構成されています。
フローの概要を順を追って解説します。
forward 関数の処理フロー
1. 前処理とキャッシュの判定
- パディング処理: 入力データに対し attention_mask を適用し、不要なパディング部分を無効化します。
- キャッシュ判定 (use_precomputed_states):
- 推論時(cache_params があり、シーケンス長が1の場合)は、過去の畳み込み状態(conv_state)と再帰状態(recurrent_state)をキャッシュから取得します。これにより計算量を削減します。
2. 特徴量の投影 (Projection)
- 入力 hidden_states を複数の経路に分岐させ、学習済みの重みを使って個別の特徴空間へ投影します。
- QKV: クエリ、キー、バリューの混合ベクトル。
- Z: ゲート制御用の出力値(後段の正規化で使用)。
- B / A: デルタルールで使用するゲートと減衰パラメータを算出するための準備。
3. 因果的畳み込み (Causal Convolution)
時系列方向の情報を集約するプロセスです。
- キャッシュ利用時: causal_conv1d_update を用いて、直前の状態のみを使用して高速に更新します。
- キャッシュ未使用時: causal_conv1d_fn (または標準の Conv1d) を使用して、時系列全体に対して畳み込みを適用し、特徴量を変換します。
- この後、混合された mixed_qkv を個別の query, key, value に分割し、形状を整えます。
4. デルタルールによるアテンション計算
このモデルの核となるステップです。
- パラメータ算出: プロジェクションの結果(aとb)から、ゲートの強さ(beta)と、再帰的な減衰を制御する係数(g)を算出します。
- アテンション適用:
- 新規計算: キャッシュがない場合、chunk_gated_delta_rule を使用してシーケンス全体のアテンションを計算します。
- 再帰的計算: キャッシュがある場合、recurrent_gated_delta_rule を使用して過去の状態から更新を行い、現在の状態を算出します。
- 状態の更新: 計算された最新の再帰状態(last_recurrent_state)を cache_params に保存し、次回の推論に備えます。
5. 正規化と最終出力
- Gated RMSNorm: アテンション出力(core_attn_out)に対し、ステップ2で計算したゲート z を用いて正規化(norm)を行います。
- 出力投影: 正規化された結果を out_proj(Linear層)に通して、モデルの隠れ層サイズへ変換して出力します。
Gated Attentionの構造
こちらは、Gated Delta Networkがくっつけた情報を整理する役割を持ったGated Attentionの構造になります。同様に__init__関数と forward 関数を眺めてみます。
class Qwen3_5Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: Qwen3_5Config, layer_idx: int):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
self.scaling = self.head_dim**-0.5
self.attention_dropout = config.attention_dropout
self.is_causal = True
self.q_proj = nn.Linear(
config.hidden_size, config.num_attention_heads * self.head_dim * 2, bias=config.attention_bias
)
self.k_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.v_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.o_proj = nn.Linear(
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
)
self.q_norm = Qwen3_5RMSNorm(self.head_dim, eps=config.rms_norm_eps) # unlike olmo, only on the head dim!
self.k_norm = Qwen3_5RMSNorm(self.head_dim, eps=config.rms_norm_eps) # thus post q_norm does not need reshape
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: tuple[torch.Tensor, torch.Tensor],
attention_mask: torch.Tensor | None,
past_key_values: Cache | None = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> tuple[torch.Tensor, torch.Tensor | None]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states, gate = torch.chunk(
self.q_proj(hidden_states).view(*input_shape, -1, self.head_dim * 2), 2, dim=-1
)
gate = gate.reshape(*input_shape, -1)
query_states = self.q_norm(query_states.view(hidden_shape)).transpose(1, 2)
key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_values is not None:
key_states, value_states = past_key_values.update(key_states, value_states, self.layer_idx)
attention_interface: Callable = ALL_ATTENTION_FUNCTIONS.get_interface(
self.config._attn_implementation, eager_attention_forward
)
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = attn_output * torch.sigmoid(gate)
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights変数一覧
| 変数名 | 説明・内容 |
|---|---|
| self.config | モデルの設定情報(Qwen3_5Configインスタンス)。 |
| self.layer_idx | 現在のレイヤー番号。 |
| self.head_dim | 各アテンションヘッドの次元数。設定がない場合は hidden_size をヘッド数で割った値。 |
| self.num_key_value_groups | GQA(Grouped Query Attention)におけるグループ数。 |
| self.scaling | アテンションスコアのスケーリング係数(head_dimの-0.5乗)。 |
| self.attention_dropout | アテンション層に適用するドロップアウト率。 |
| self.is_causal | 因果的(Causal)アテンションであるかを示すフラグ(True固定)。 |
| self.q_proj | クエリ(Query)投影用の線形層。 |
| self.k_proj | キー(Key)投影用の線形層。 |
| self.v_proj | バリュー(Value)投影用の線形層。 |
| self.o_proj | 出力(Output)投影用の線形層。 |
| self.q_norm | クエリに対して適用するRMS正規化層。 |
| self.k_norm | キーに対して適用するRMS正規化層。 |
forward関数のフロー
1. 前処理と射影 (Projection)
- 次元調整: 入力テンソルの形状を整理します。
- Q/Gateの算出: q_proj を通して計算された出力から、Query(クエリ)とGate(ゲート制御用信号)を分離します。
- K/Vの算出: k_proj、v_proj を通してKey(キー)とValue(バリュー)を算出します。
2. 正規化と正規化後の調整
- RMSNormの適用: QueryとKeyに対して、定義された正規化(q_norm, k_norm)を適用し、数値の安定化を図ります。
- 次元変換: アテンション計算に適した形状(transpose)へ入れ替えます。
3. 位置情報の埋め込み (RoPE)
- 回転位置埋め込み (Rotary Positional Embedding): QueryとKeyに対し、apply_rotary_pos_emb を使って位置情報(cos, sin)を付与します。これにより、モデルがトークンの位置関係を認識できるようになります。
4. KVキャッシュの更新 (推論時)
- キャッシュ管理: past_key_values が存在する場合、以前のトークンのKey/Valueを保持しているキャッシュを更新し、計算量を削減します。
5. アテンション計算の実行
- 実装の選択: モデルの設定(_attn_implementation)に基づき、最適化されたアテンション関数を呼び出します(FlashAttentionなど)。
- 計算実行: Query, Key, Value、マスク、ドロップアウト率、スケーリング係数を用いてアテンション出力を算出します。
6. 出力の加工とゲート機構の適用
- 形状復元: 出力テンソルを元の形状に戻します。
- ゲート処理: 最初に生成した gate(シグモイド関数を通したもの)をアテンション出力に掛け合わせます。これにより、情報の重要度に応じて動的にフィルタリングを行います。
7. 最終出力
- 出力射影: 最後に o_proj に通して、モデルの次元サイズへ変換し、結果としてのアテンション出力とウェイトを返します。
FFN(Feed Forward Network) 機構
これらの処理を受けて後ろに待ってるのは一時的に次元拡張をするFFNなんですが、ではこれはどうなっているでしょうか。これは Qwen3_5MLP クラスで実現されています。
class Qwen3_5MLP(nn.Module):
def __init__(self, config: Qwen3_5Config, intermediate_size: int):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj非常にforward関数がシンプルですね。アクティベーション関数SiLUを使用して実行される構造をそのままプログラムコードで表現したような内容になっています。
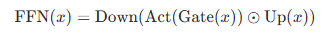
Downのかっこの中はつまり、
- hiddenテンソルの中身の次元数引き上げが行われ
- そこにアクティベーション関数が掛け合わされたテンソル
であり、それをさらにDownプロジェクションされてるわけですから、それが一気に表現された結果がOutputしているということになります。
アクティベーション関数はどこで指定してるの?というところですが、ACT2FN[config.hidden_act] で定義されています。このACT2FNはtransformers/activations.py で定義されています。
ACT2CLS = {
"gelu": GELUActivation,
"gelu_10": (ClippedGELUActivation, {"min": -10, "max": 10}),
"gelu_fast": FastGELUActivation,
"gelu_new": NewGELUActivation,
"gelu_python": (GELUActivation, {"use_gelu_python": True}),
"gelu_pytorch_tanh": GELUTanh,
"gelu_python_tanh": (GELUTanh, {"use_gelu_tanh_python": True}),
"gelu_accurate": AccurateGELUActivation,
"hardswish": nn.Hardswish,
"laplace": LaplaceActivation,
"leaky_relu": nn.LeakyReLU,
"linear": LinearActivation,
"mish": MishActivation,
"quick_gelu": QuickGELUActivation,
"relu": nn.ReLU,
"relu2": ReLUSquaredActivation,
"relu6": nn.ReLU6,
"sigmoid": nn.Sigmoid,
"silu": SiLUActivation,
"swish": nn.SiLU,
"tanh": nn.Tanh,
"prelu": nn.PReLU,
"xielu": XIELUActivation,
}
ACT2FN = ClassInstantier(ACT2CLS)
定義の下から5行目にsiluが定義されています。configにてsiluの定義が存在しており、それが引っ張り出されるという形になるようです。なので、SiLUActivationというものが格納されているはずです。
層は重ねれば重ねるほど表現が洗練される・・・・とは?
Transformerもそうですが、この手のデコーダーは層を重ねれば重ねるほど参照情報の領域を広げていきます。より大きなパラメータを持つニューラルネットワークが汎用的な能力が高いというのはそのことに端を発しており、実は層を重ねるにつれて例えば以下のような変化が起きます。
1層目:構文的接続のみを重視
「彼はリンゴをかじった。それは」
(理由:主語や目的語の後に続く、最も一般的な指示代名詞を探している)10層目:物理的な因果関係を重視
「彼はリンゴをかじった。果汁が口の中に広がり、」
(理由:かじるという動作の直後に起こる物理的な感覚を予測している)20層目:文体やシーンの雰囲気を重視
「彼はリンゴをかじった。幼い日の懐かしい記憶が、まるで色褪せた写真のように」
(理由:物理的なリンゴから、それをきっかけとした内面的なエピソードへの接続を試みている)24層目:最終的な一貫性と文脈的結論を重視
「彼はリンゴをかじった。甘酸っぱい果汁が口いっぱいに広がり、かつて祖母と過ごした夏の終わりの記憶が鮮明に蘇った。」
(理由:文脈、語彙の選択、情緒的完結、すべてを考慮した「最終的な予測」)
※以下はあくまで思慮を広げるイメージである点に気を付けてください。
そうした思慮範囲の広がりによって、確率分布は変化し、次にやってくるトークン予測情報が出てきた結果、それが出力されるわけです。なので、後の層になればなるほど「細かい」ところの修正が行われるという風に考えればよいのかなと思います。
逆に前半の層のデータが崩れると、そもそも文章として成り立たない状況が発生することになります。過去にWhisperのファインチューニングを行ってた時は、末尾層を基準にファインチューニング個所を限定してたのは、容量削減が求められたことと同時に、当時のWhisperの能力的に前半層のモデルデータは「すでに完成された状態にあったため」というのが実際のところです。
経験というのもそれなりに役立つはずだ
私は決して天才の類ではありません。これまでの人生を通じて検証してきたことや分析してきたこと、手探りでもろもろ取り組んできたこと、様々な情報共有を重ねてきた結果、今のようなことができるにすぎませんで、私はよくこの技術を「技術をなぞるスキル」と呼んでいます。
先人方のくみ上げてきたものがだれにも理解されないのではなく、わかりやすく解釈して伝えることだけが取り柄であり、そうしたものが末端まで浸透したら私は不要になるような、そんなつなぎであるだけの存在です。でも、DeepLearningの世界は不思議がまだまだ隠れていて、それを素人の私が解析し続けることで、より考え方が広まりやすくなって、正しく人工知能をオペレーションできるのであれば、面白おかしく取り組んでみようと考えています。
エンジニアではなくなりますが、引き続き面白そうなものを見つけて掘り下げていきたく思っております。

コメント