

せっかく調査の際に構成図を書いたので、それを貼っておきます。
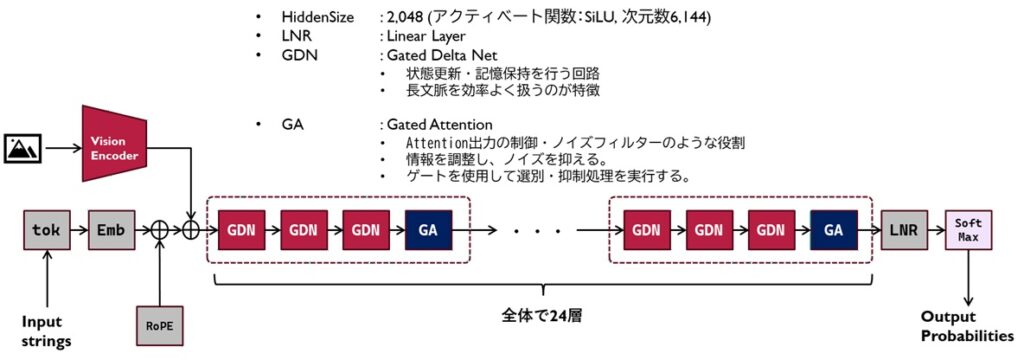
Qwen3.5の特徴は、それ以前に出てたQwen3-Nextの構成を踏襲しているところです。
一般的に、上図のGDN/GAは全く同じ仕組みが連なっていくものですが、Qwen3-NextではGDNとGAという形で少し異なる層を3:1の比率で並べており、これが1つの親ブロックみたいになってるのが特徴です。
そういう意味で、Qwen3.5というのは、普通のGQAで構成され、VISIONエンコーダを備えたQwen3-VLシリーズと特殊なAttention構造を持つQwen3-Nextを合体させたようなシリーズなんですね。
その詳細は上図に記述していますが、「覚えて、覚えて、覚えて、落ち着いて」といった具合に並んでいて、ハルシネーション抑止力を持たせつつも長文が来ても忘却が発生しないような構成が取られています。なお、2BモデルはDenseモデルですので、アクティベーション関数がSiLUの従来型の全結合層が構成されています。
ミッドレンジモデルのQwen3.5-35B-A3Bではその全結合層の部分がSparse MoEになっていたりします。
ところでこのモデル、特徴というのかなんというのかわかりませんが、処理速度がアーキテクチャの違いでそれほど上下しないというところがあります。なので、Qwen3.5-4Bなどを動かした場合に、出力こそ高速なんだけど読み出しが思ったより遅い・・って思うことがちょいちょいありました。
ですが、それ以外については申し分なしのなかなか強力なモデルだなぁというのを痛感します。これを日本語特化出来たら、たぶんそれだけで結構いろんな分野に応用できるのではないかな?という気がしますね。


コメント