
気持ち的にはタイトルにも「!」をつけたい!
一時は「出る出る詐欺」とまで言われてたGemma-4がついに2026年4月3日にリリースされてたということで、朝からアゲアゲです。私この執筆をAM5時から開始しています。
https://huggingface.co/blog/gemma4 にて紹介が書かれてましたので、さっそく確認してまいりましょう。
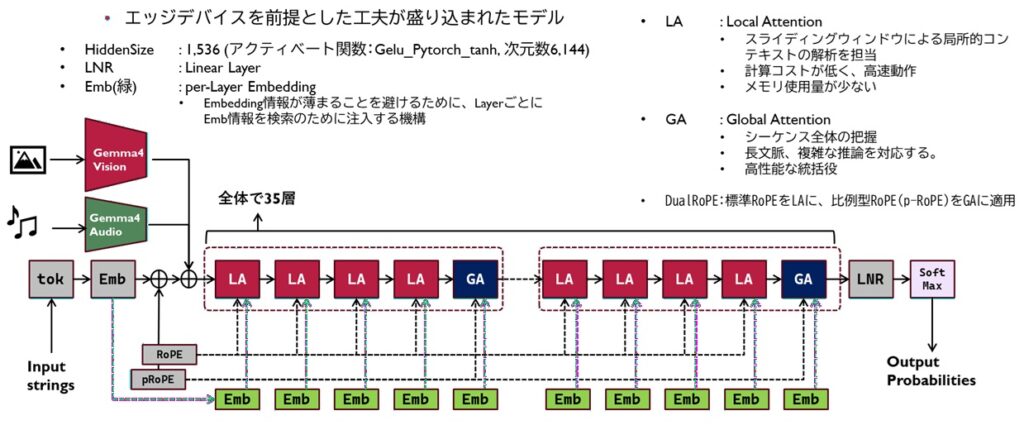
アーキテクチャ上の特徴
アーキテクチャの特徴としてはこんな模様です。
Alternating local sliding-window and global full-context attention layers.
「局所的スライディングウィンドウ処理と大域的フルコンテキストAttention層を交互に配置したアーキテクチャ」ということで、128kトークン/256kトークンを収容可能としつつもメモリ消費が非常に少ないアーキテクチャを採用しているんだと思います。
またLA(LocalAttention)とGA(GlobalAttention)を4:1の比率で配置し、スライディングウィンドウ処理を対応するLocalAttentionで効率よく文脈を形成し、後述のRoPE構造を使用してGlobalAttentionにて全体を把握するという非常に協調性を意識したつくりになっていることがうかがえます。
小規模な高密度モデルでは512トークンのスライディングウィンドウを使用する一方、大規模モデルでは1024トークンを採用しています。それによって、小規模モデルと大規模モデルとで最大コンテキスト長が変わってきます。
Dual RoPE configurations:
長いコンテキスト処理を可能にするため、スライディング層には標準的なRoPEを、グローバル層には比例型RoPEを採用しています。
Per-Layer Embeddings (PLE):
デコーダーの各層に小さな残差信号を供給する第2の埋め込みテーブルを実装しています。
Shared KV Cache:
モデルの最終N層では、先行する層からキー・バリュー状態を再利用することで、冗長なKV投影処理を省略しています。
Vision encoder:
学習済みの2次元位置情報と多次元RoPEを採用しています。元のアスペクト比を保持しつつ、画像を70、140、280、560、1120といった複数の異なるトークンバジェット(トークンの予算)で符号化することが可能です。
Audio encoder:
Gemma-3nに採用されている基本アーキテクチャと同じベースアーキテクチャを採用したUSMスタイルのコンフォーマーです。
Switch Reasoning model:
Reasoning, non-Reasoning切り替えが可能なようです。このあたりはjinjaテンプレートをまず見ないといけないなぁ・・・・
構造としては以下の通りになっています。PLEという構造はこれより前のモデルであるGemma3nから受け継いでさらにエンハンスしたものと予想されます。
ラインナップと性能
モデルのラインアップは E2B, E4B, 26B-A4B, 31Bとなっており、MoEを採用しているのは1種類、残りはDenseモデルですね。E2B, E4BはGemma-3nの系譜から連なるいわゆる「マトリョーシカ製法」のモデルです。
| Model | Parameter Size | Context Window | Checkpoints |
|---|---|---|---|
| Gemma 4 E2B | 2.3B effective, 5.1B with embeddings | 128k | base, IT |
| Gemma 4 E4B | 4.5B effective, 8B with embeddings | 128k | base, IT |
| Gemma 4 31B | 31B dense model | 256K | base, IT |
| Gemma 4 26B A4B | mixture-of-experts with 4B activated/26B total parameters | 256K | base, IT |
推奨サンプリングパラメータとしては以下が指定されていました。一般的なReasoningモデルと同等ですね。top_kが少しでかめです。
temperature=1.0top_p=0.95top_k=64
性能は以下の通り示されておりまして、結構これいいんじゃないでしょうか?
比較対象がGemma3-27Bなのですが、
| Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B (no think) |
|
|---|---|---|---|---|---|
| MMLU Pro | 85.20% | 82.60% | 69.40% | 60.00% | 67.60% |
| AIME 2026 no tools | 89.20% | 88.30% | 42.50% | 37.50% | 20.80% |
| LiveCodeBench v6 | 80.00% | 77.10% | 52.00% | 44.00% | 29.10% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 | 110 |
| GPQA Diamond | 84.30% | 82.30% | 58.60% | 43.40% | 42.40% |
| Tau2 (average over 3) | 76.90% | 68.20% | 42.20% | 24.50% | 16.20% |
| HLE no tools | 19.50% | 8.70% | – | – | – |
| HLE with search | 26.50% | 17.20% | – | – | – |
| BigBench Extra Hard | 74.40% | 64.80% | 33.10% | 21.90% | 19.30% |
| MMMLU | 88.40% | 86.30% | 76.60% | 67.40% | 70.70% |
| Vision | |||||
| MMMU Pro | 76.90% | 73.80% | 52.60% | 44.20% | 49.70% |
| OmniDocBench 1.5 (average edit distance, lower is better) | 0.131 | 0.149 | 0.181 | 0.29 | 0.365 |
| MATH-Vision | 85.60% | 82.40% | 59.50% | 52.40% | 46.00% |
| MedXPertQA MM | 61.30% | 58.10% | 28.70% | 23.50% | – |
| Audio | |||||
| CoVoST | – | – | 35.54 | 33.47 | – |
| FLEURS (lower is better) | – | – | 0.08 | 0.09 | – |
| Long Context | |||||
| MRCR v2 8 needle 128k (average) | 66.40% | 44.10% | 25.40% | 19.10% | 13.50% |