

よくよく考えてみれば
llm-jp4のアーキテクチャを整理してる際にふと気づいたことがあります。
「Tokenizerってどうやって作ってるんだろう?」
お前そんなことすら知らねーのか!?と言われそうですが、全く意識したことがありませんでした(;´・ω・)
今回、llm-jp4のことを調べた際に、旧式アーキテクチャとあの学習法だけでそこまで向上するものなんだろうか・・・とか思いつつこの際ちゃんと調べるかと取り組んでみると、なんとまぁ世界観が一気に変わりました。
トークナイザとは?
トークナイザというのは、文字あるいは単語の並びといったものを数値のリスト配列に変換するもので、私が例える場合、よく「ASCIIコード表を連想してほしい」と言います。
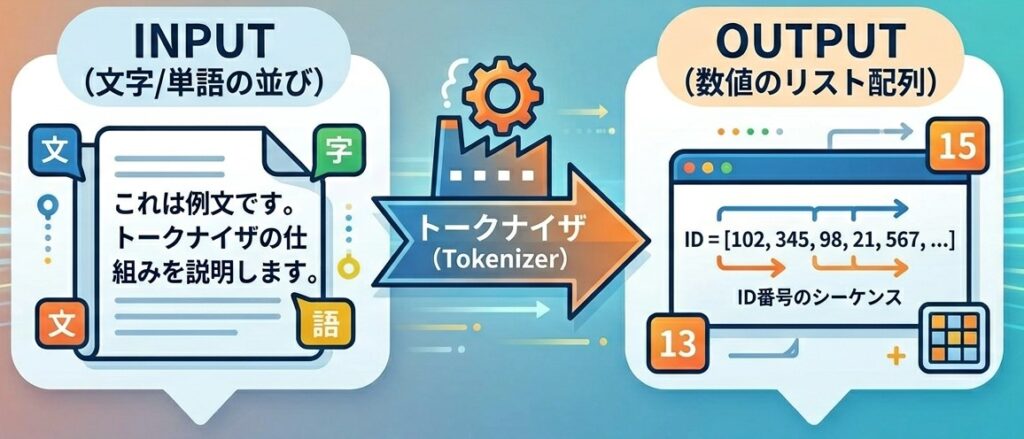
ASCIIコード表は、コンピュータに表示させる文字を数値というコードに変換させる際の対応表であり、プログラムを記述する際に特定のキャラクタを用いて何らかの処理をさせたい場合にある意味必携となる表でした。
当時はこのコード表は「規格」として打ち立てられたものであり、その規格内容は人間が決めるものでした。しかし今の時代のトークナイザはそれでは立ち行かないほど多言語、多様な文字を相手にしますので現実的ではありません。そこで、トークナイザの作り方をざっくり説明書きしてみました。
サブワードという言葉
tokenizerを考えるとき、まず登場するキーワードが「サブワード」です。「サブワード」とは何か?を簡単に述べると「単語」と「文字」の中間に位置づけられる、中間語に相当します。
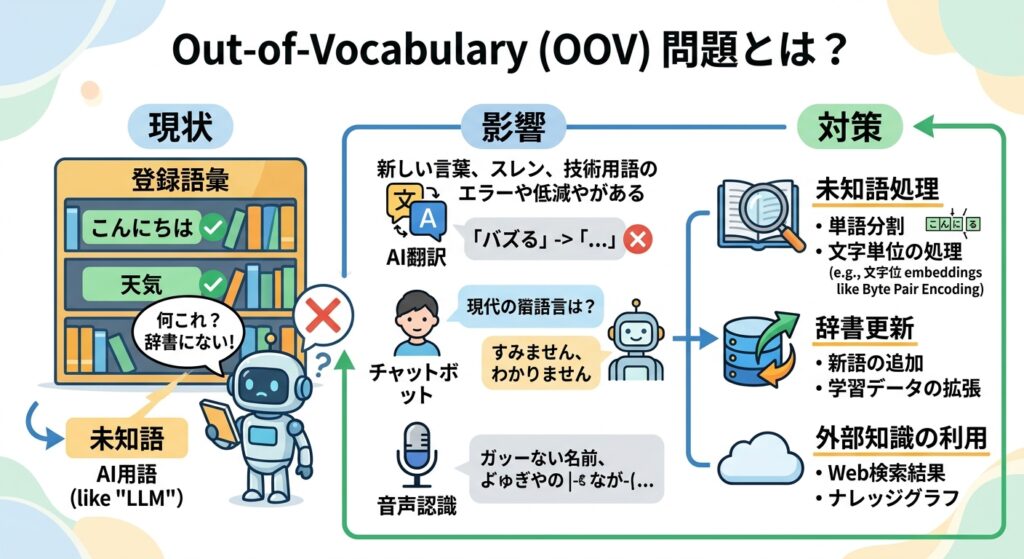
2015年以前、トークナイザは単語単位で組み上げていくのが一般的だったといわれています。ところが、それでは単語以外の文字列に対して「識別不能」として処理されてしまい、正しく自然言語処理が行えなくなる Out-of-Vocaburary問題が発生していたといわれています。
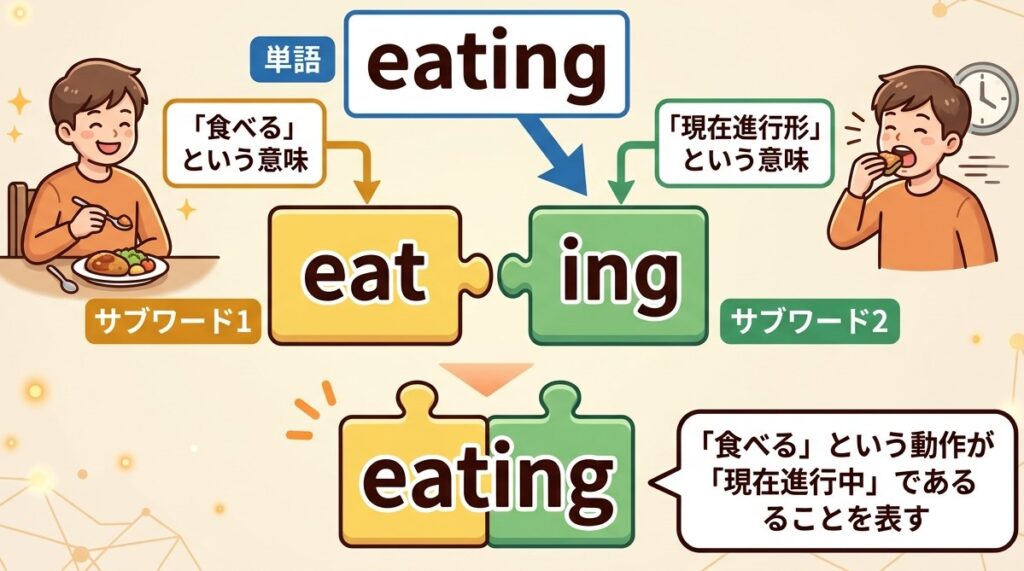
実際にはサブワードは、単語と「単語じゃないんだけど単語のように決まって頻出するもの」を合わせたようなものととらえるとよいかもしれません。代表的なものとしてよく挙がるのが「##ing」です。単語というわけではありませんが、その末尾につくことで意味を持つようなものというのは、サブワードとしてトークンIDが割り振られるわけですね。
このサブワードの概念は2015年エディンバラ大学の研究者(Rico Sennrichら)が提唱したといわれており、そのころ、もともとは文字列の圧縮技術としてBPEが使われている中で、こうしたAI方面にそのアルゴリズムが適用できる点で再発見されたといわれています。
なぜこうしたサブワードがトークナイズで重要かというと、こうして識別不能を避ける意図、そして1文字単位で推論するより圧倒的に効率的であることが理由となります。
tokenizerを作る方式・手順
今どきのトークナイザを作る方法、それはずばり
「大量のテキストデータから統計的に作成する」
ことが主流になっています。
つまり、人の手に完全に頼るわけでなく、ある一定の自動化プロセスのもとで作成することになります。
プレトークナイズ(前準備処理)
以下のことを行い、ざっくりした単語の単位で字句解析処理を行っていきます。
- テキストのクリーニング
余計な空白の削除、大小文字の統一、記号の整理などを行い、処理しやすいようにテキストを変換します - 字句解析実行して、単語(らしきもの)を抽出していきます
サブワードの抽出
英語向けのアルゴリズムではありますが、BPE(Byte-pair Encoding)に従って説明をするとこうなります。
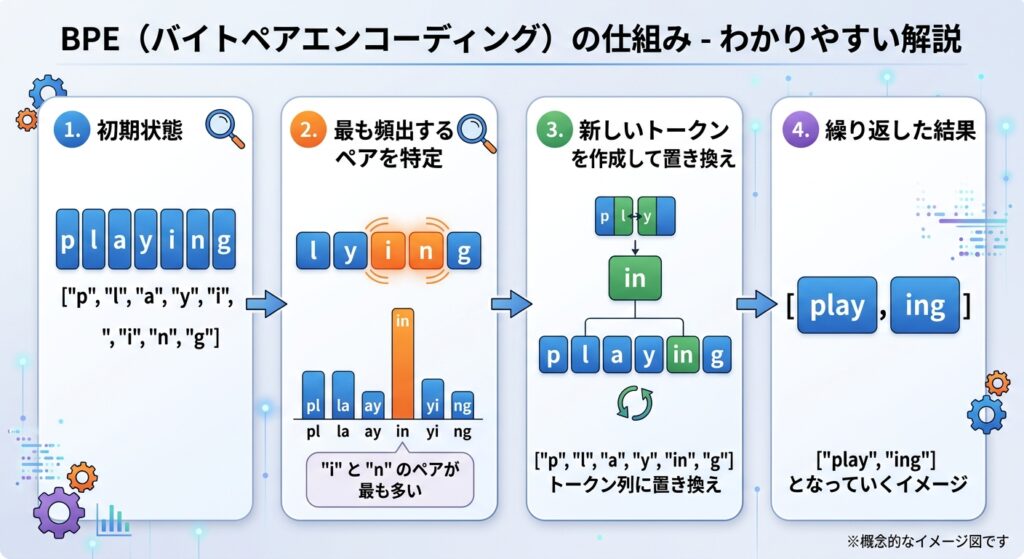
- 抽出された文字列で
["p","l","a","y","i","n","g"]があるとします。 - この文字列の中で、どの文字のペアが最も一番使われてるかを統計的に割り出します。
この例では“i”と”n”が頻出したと想定します。 - “i”,”n”が頻出してると割り出されたと判明したため、これをくっつけた”in”というトークンを新たに1つ作ります。
- これにより、トークンの並びとしては
["p","l","a","y","in","g"]というトークン列という形に置き換えられます。ここからさらに手順②をやり直していきます。 - これを繰り返していくことで、当初の文字の羅列は、
["play","ing"]となっていくようなイメージです。
実際にはコーパスデータの量は非常に膨大で、もっとたくさんのサブワードがこうして抽出されていきます。そのトークナイザに設定した目標Vocab数に到達されるまでこのループが延々と繰り返される、ということになります。
結果として、非常に膨大なサブワードのリストが出力されることになります。
IDの割り当て
得られたサブワードのリストに、IDを割り振ります。互換性を重視する場合は、元にしたトークナイザにID体系を踏襲する必要があるでしょうし、そうでなければ頭から順に値を割り振っていけばよいのだと考えられます。
割り当てる数値は10進数でよいかと思います。実際、LLM/SLMが出力するトークン列も大体が10進数で表記されたリスト配列という形で出力されます。
特殊トークンの割り当て
最後に、特殊トークンを定義します。代表的なものとして以下のようなものがあります。
トークンIDは、サブワードリストに含まれない数値を指定し、これを決定します。
- <EOS> End of Sentence :トークン列の終わりを示すトークン
- <PAD> Padding :長さを切りそろえるために加えられる不可視トークン
- <UNK> Unknown :識別不能トークン
llm-jp4 tokenizerでは?
じゃぁ、llm-jp4 tokenizerではどんなトークナイズがなされるように作られてるかを見てみます。
llm-jp4はわかりやすく言うと「多言語対応はせずに、日本語・英語・コードという3種類に特化する形で作られたトークナイザ」が作られています。Googleの日本人エンジニアだった工藤拓氏らが言語に依存しないSentencePieceというTokenizer向けライブラリをリリースしており、このトークナイザもそれを利用しています。BPEでは英語に対する適合性は高いのですが、日本語に対する適合性はあまり高くないため、SentencePieceが持つUnigramモードというものを使用して構築されています。
マルチリンガルの道を捨て、あくまで日本語との親和性を最優先として開発したことで、日本語推論の性能が飛躍的に向上することになっており、それこそがパラメタ数によらないAI応答性能の高さを実現している一つの要因になっています。

コメント