

うちのブログをご覧になってくださる人からフィードバックが!
なかなか書きっぱなしでフィードバックが返ってこない私のこのブログなんですけれども、有難いことにX.comでディープラーニングモデルのことを色々リサーチなさってるきしださん(https://x.com/kis)が当ブログをご覧になり、フィードバックを返してくださりました。ヤバい、超うれしい。
どうやら教えてくださった内容を拝見すると、Qwen3.6-35B-A3Bにおいて、一部ExpertsをCPUにオフロードすることにより、高速化される見込みがあるとのこと。続く話の中で、FFNはどちらかというとCPUが得意とする処理であり、これをCPUに出すことでさらなる高速化が果たせたことがあるとのことで。
このあたり、PCIe間の通信も気になったのですが、何事も取り組むことに価値があるということで、試しに実行してみた次第です。
MoEとDense
Qwen3.6-35B-A3Bは、所謂 Mixture of Experts というモデルでして、Attentionを抜けた後、まずGate層で負荷分散をするように(ロードバランサみたいにって言うとわかりやすい?)、マッチすると思われるExpertsを選別してくぐらせるような動作をします。こうすることで、情報の洗練時に限定的な情報のみをくぐらせるようにすることで、その計算処理量を軽減するという特性を持っています。きしださんの場合、そのExpertsをCPUにオフロードさせることにより、うまく役割分担をさせ、計算を効率化させようとしているようです。
これに対して、私が利用している Qwen3.5-9B モデルは、Denseモデルと言われていて、情報の洗練時は1本線で構成されたMulti-LayerPerceptron(FeedForwardNetwork:FFNともいう)にくぐらせ、ブロックが保有するすべての情報から情報を洗練させるような処理を行います。MoEに比べると速度は劣りますが、全結合層構成をとってるため、情報の網羅性が高く、正確性(品質的な性能)で言うと上という特性があります。
DenseモデルにおけるCPUオフロード指定はどうする?
MoEモデルを相手にしたきしださんのケース
きしださんの場合、MoEですので、以下のような指定を行って処理をしていたようです。koboldcpp.exeを使用して、–overridetensors オプションで指定している箇所が該当します。
koboldcpp.exe \
--overridetensors "blk\.([0-9]*[05])\.ffn_.*_exps\.=CPU" \
--model "D:\dev\gguf\unsloth\Qwen3-30B-A3B-GGUF\Qwen3-30B-A3B-UD-Q3_K_XL.gguf" \
--gpulayers 48overridetensorsは、以下構成されるニューラルネットワークのパーツを正規表現で指定したものになります。以下はQwen-MoEモデルにおける第16層を例に、パターンに引っかかるところを青枠で囲んでみたものなんですが、Gate層、Up層、Down層丸ごと指定していることが分かります。

Denseモデルを相手にした私の場合
では私はどうしたらよいでしょう。DenseそうはMoEと違ってGate層なるものはありません。単純にUp層、Activation層、Down層があるだけです。
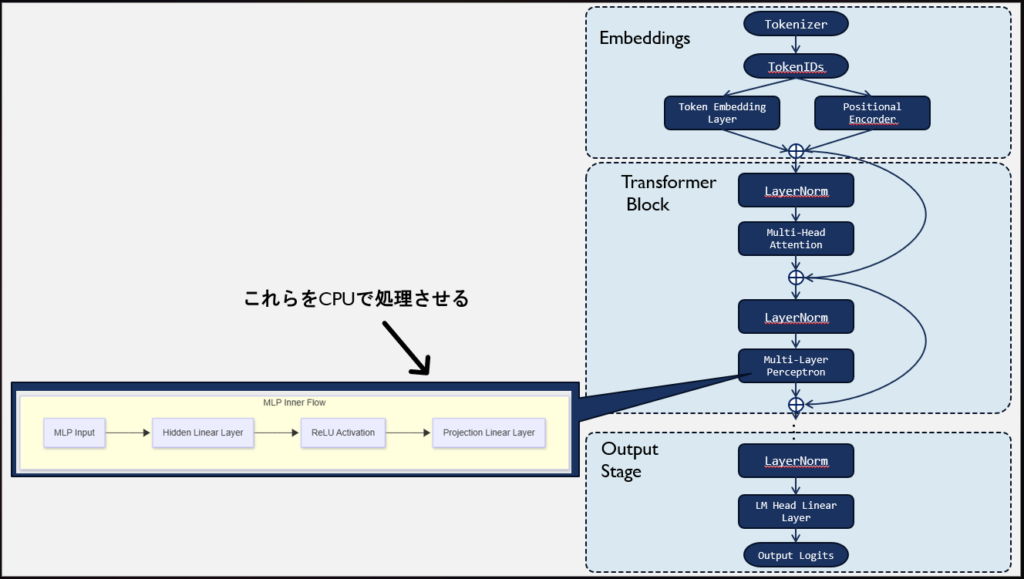
これに対して、当方は llama.cpp を指定してますので、以下のような指定をしました。
/opt/llama/bin/llama-server \
--model /opt/llama/models/Qwen3.5-9B-UD-Q4_K_XL.gguf \
-t 4 -np 1 --prio 2 --temp 1.0 --top-p 0.95 --top-k 20 --min-p 0.00 \
--host 0.0.0.0 --port 8001 --device CUDA0 -mg 0 \
-ctv q8_0 -ctk q8_0 --fit off --no-warmup --no-cache-prompt -fa on --cache-ram 0 \
--override-tensor "blk\.([0-9]*[05])\.ffn_.*\.=CPU" \
-c 65535 --reasoning onさて、果たして速度はいかほどに・・・?通常、GPUだけで処理させるとおよそ33tok/sの速度が出てましたが・・
期待値に至らず。だが・・・・
実行した結果は以下の通りとなりました。
prompt eval time = 1425.11 ms / 26 tokens ( 54.81 ms per token, 18.24 tokens per second)
eval time = 149692.25 ms / 2599 tokens ( 57.60 ms per token, 17.36 tokens per second)(´・ω・`)
え、おそい・・・・とは思ったものの、思ったほど遅くはなりませんでした。大体半分ぐらい。そして気づきました。
/opt/llama/bin/llama-server \
--model /opt/llama/models/Qwen3.5-9B-UD-Q4_K_XL.gguf \
-t 4 -np 1 --prio 2 --temp 1.0 --top-p 0.95 --top-k 20 --min-p 0.00 \
--host 0.0.0.0 --port 8001 --device CUDA0 -mg 0 \
-ctv q8_0 -ctk q8_0 --fit off --no-warmup --no-cache-prompt -fa on --cache-ram 0 \
--override-tensor "blk\.([0-9]*[05])\.ffn_.*\.=CPU" \
-c 65535 --reasoning on-t 引数増やしたら早くなるんじゃね?+ (o゚・∀・) + ワクワクテカテカ +
-t 引数は、CPUのスレッド数上限を指定する引数です。以前は搭載してたCPUのスレッド数が8だったので、その半分の4を上限にしてましたが、今積んでるCPUは28スレッドもありますんで、ワンチャンこれで高速化が期待できるんじゃね?と思い。試しに動かしてみました。
/opt/llama/bin/llama-server \
--model /opt/llama/models/Qwen3.5-9B-UD-Q4_K_XL.gguf \
-t 20 -np 1 --prio 2 --temp 1.0 --top-p 0.95 --top-k 20 --min-p 0.00 \
--host 0.0.0.0 --port 8001 --device CUDA0 -mg 0 \
-ctv q8_0 -ctk q8_0 --fit off --no-warmup --no-cache-prompt -fa on --cache-ram 0 \
--override-tensor "blk\.([0-9]*[05])\.ffn_.*\.=CPU" \
-c 65535 --reasoning on併せて、PCIeバスの通信量なども元々気になってましたので、nvtopを組み込んでその帯域も計測してみました。以下、要素別でお伝えします。
速度
速度は上昇しました。チョッとだけ。

CPU使用率
スレッド上限を20にすることでたっぷり使ってくれたようです。多コアCPUを最大限使った経験があまりないので、一瞬おったまげました。
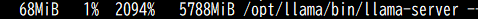
PCI-Express帯域
今回CPUとPCI-Expressバスを介してGPUは連携をしていることもあり、そのバス帯域も見て見ましたが、意外な結果が出ました。

GPUでの受信が19.22MiB/s、送信が3.29MiB/sという具合に非常にかわいい結果になりました。実は、LLM/SLMのニューラルネットワークにおいて、その層の中の値をばらすと非常に大きな帯域を必要とするんですが、その1本線を通り抜ける間の情報量は非常に少なく、このように非常に小さな値で済んでしまうのが実態です。この経過もしばらく注視しましたが、結局これがGiB/sの域に達することはありませんでした。
なので、Layer分散などをした場合はそんなに大きな速度損失は出てこないのが実際で、しかしながらTensor分散とかRow分散などを選択した場合はそれなりの帯域が流れることになるのでしょう、その場合においてはパフォーマンスダウンは十分に考えられます。
結論
今回のケースでは、おそらくCPUの能力の低さが原因で期待する速度に達しませんでしたが、現行のXeonCPUなどであれば、おそらくはきしださんのおっしゃったような結果が期待できるのかもしれません。
何しろ私が使っているCPUは第5世代と言われるBroadwell-EPコアであるXeon E5-2690v4です。これが現行CPUとなると実は相当に高速な代物になっていますので、ぜひそれで試す機会があれば・・・・・・!と感じた今日この頃です。

コメント