
アーキテクチャの違いで言語モデルの動きに差が出るのか?
というところがなかなかピンとこないことがあります。特にDeepLearningモデルの領域では、ことあるごとに新しい仕組みが生まれては世代が変わり、それが学習の差によって出るものなのか、アーキテクチャの差によって出るものなのかがよくわかりません。今回その比較をしてみたいと思います。
比較に使用するのはタイトルにもありますように、
所謂国産モデルとして最近一皮剥けてくれたllm-jp-4-8b-thinkingモデル
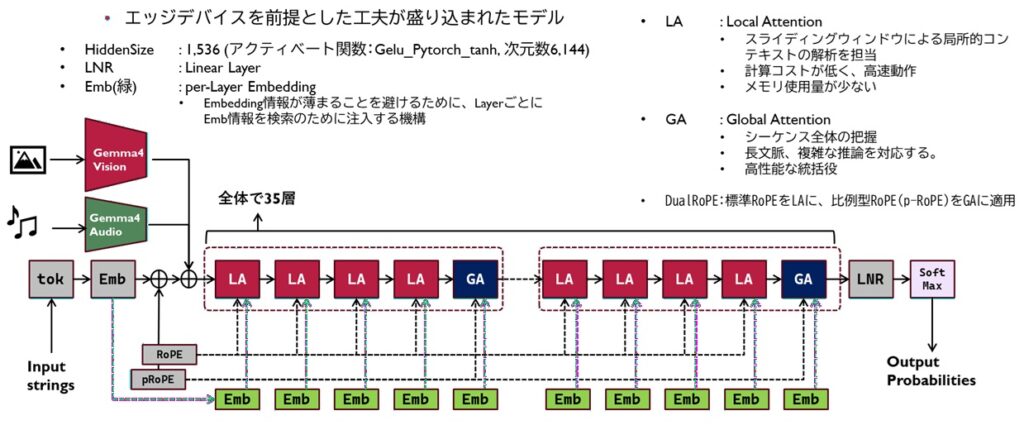
もう一つはGoogle DeepmindからリリースされたマルチモーダルモデルであるGemma-4-E4Bです。
※画像はもう少し小さなGemma-4-E2Bですが、構造のポイントは同じです。
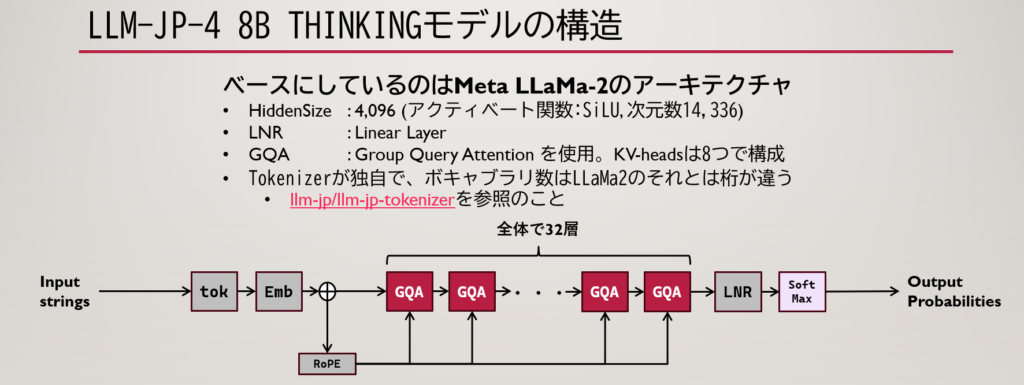
アーキテクチャそれ自体はllm-jp-4-8bではGQA(Group Query Attention)を先進的に適用したLLaMa-2ベースで組み上げられており、Tokenizerの更新、学習法の工夫によって国産として恥ずかしくない性能をたたき出しました。それまで32kぐらいが精いっぱいだった国産LLMのコンテキスト長を64kまで引き上げており、これが非常に大きな存在感を放っています。
これに対するGemma-4-E4Bでは、LocalAttention=4:GlobalAttention=1の5層構造を1セットとして積層構造にしていったほか、エッジモデルとしても使えるような工夫をたくさん盛り込んだかなり特殊なニューラルネットワークが構成されています。アリババのQwen、NVIDIAのMambaシリーズとはまた違ったAttention構造を有した特殊性の高い内容となっています。
ぱっと動かしてみたときの印象としては
実際に動かすと、割とはっきりわかるのは「ターンを繰り返すうちにllm-jp-4-8bのほうが遅くなってる気がする」ということでした。
そこで、その劣化具合の比較を行ってみました。そして、これが何の違いが原因で、どういう風に影響したのかについて論じたいと思います。
テストケースはllama.cppにおけるKVキャッシュ量子化についてと同様の内容で進めており、3ターンそれぞれの出力状況をベースにしています。内容も同じテストケースとしていて、Javascriptをベースにしたブロック崩しゲームの作成をしてもらっています。
使用しているGPUはNVIDIA A4000を使用しています。
モデル別 出力速度および低下率の比較表(条件統一版)
※両モデルともに、短いプロンプトからスタートし、コンテキストが同程度(約7,000トークン)まで蓄積していく3ターン分のデータを比較しています。
| ターン | モデル名 | 入力トークン数 | 出力トークン数 | 出力速度 (tokens/s) | 速度低下率 (ターン1比) |
|---|---|---|---|---|---|
| 1 (初期状態) |
LLM-JP-4 8B Thinking | 119 | 3,197 | 64.65 | – |
| Gemma-4 E4B It | 34 | 3,723 | 78.57 | – | |
| 2 (中間) |
LLM-JP-4 8B Thinking | 3,394 | 4,364 | 57.07 | -11.7% |
| Gemma-4 E4B It | 3,089 | 4,836 | 73.24 | -6.8% | |
| 3 (蓄積後) |
LLM-JP-4 8B Thinking | 7,658 | 1,840 | 52.78 | -18.3% |
| Gemma-4 E4B It | 7,262 | 4,224 | 69.44 | -11.6% |
次に、ここで出た速度を縦軸に、トークン数を横軸にして、出力速度の比較、ターン毎の速度劣化率を表現してみました。(Powered by Gemini 3.1 Pro)
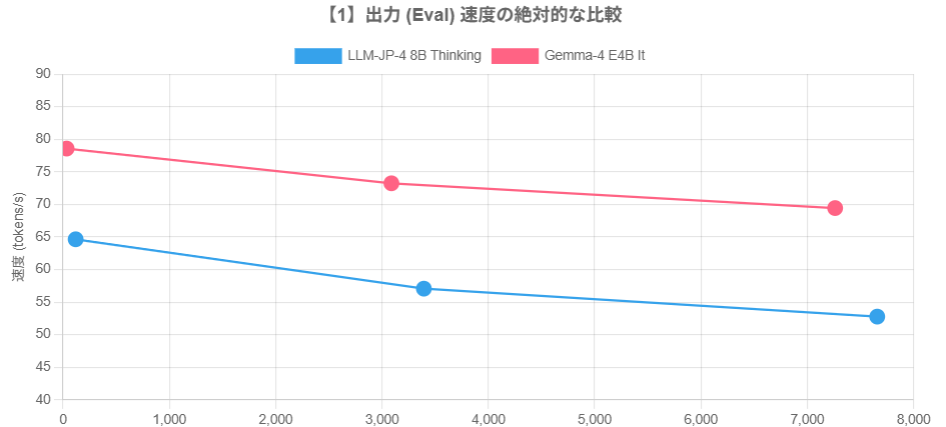
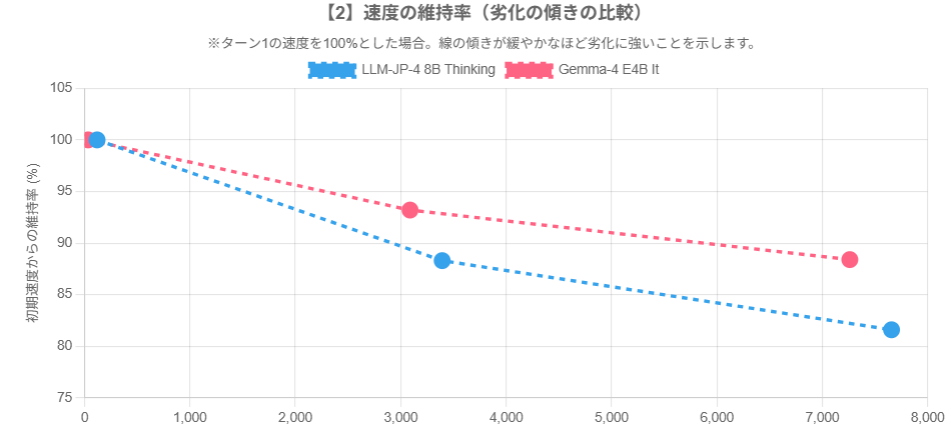
これを見ると、どうやらllm-jp-4では多くのトークンをため込むとともに、入力・出力とともにパフォーマンスが低下していってることが分かります。Gemma-4ではその劣化が小さいあるいは横ばいになっているように見えます。
アーキテクチャによって変化する速度傾向
LLMがテキストを生成(出力)する際、ボトルネックになるのは計算処理そのものではなく、「1トークン出力するたびに、過去の文脈データ(KVキャッシュ)をVRAMから読み直す際のメモリ転送量」です。文脈が長くなるほど読み込むデータ量が増えるため、速度は低下します。
この原理を踏まえ、ログに出力されたアーキテクチャの情報を比較すると、Gemma-4には「長文脈でもKVキャッシュの転送量を極限まで抑える最新の仕組み」が搭載されていることがわかります。
具体的な要因は以下の3点です。
要因①:Sliding Window Attention(SWA)の有無
- LLM-JP-4: 過去のすべてのトークンを均等に参照する「Global Attention」を採用しています。そのため、トークンが蓄積した分だけ毎回のデータ読み込み量が純粋に増加し、速度が落ちていきます。
- Gemma-4: ログに gemma4.attention.sliding_window = 512 とある通り、スライディング・ウィンドウ・アテンションを採用しています。
これは「直近512トークンなど、一定範囲の記憶を重点的に参照し、古い記憶の計算負荷を切り捨てる」仕組みです。これにより、文脈が数千トークンになっても計算対象が増えすぎず、速度低下を防いでいます。
要因②:レイヤー間でのKVキャッシュ共有(Shared KV Layers)
- Gemma-4: ログにある gemma4.attention.shared_kv_layers = 18 という設定が非常に強力です。通常のLLMは全レイヤー(Gemma-4なら42層)それぞれで独自の過去記憶を持ちますが、Gemma-4は多くの層で記憶データを「共有」しています。これにより、VRAMに保持・転送すべきデータ量が劇的に削減されています。(LLM-JP-4にはこの共有機構はないので、層単位で独自の過去記憶をもって言葉を紡ぎだしてることになります。)
要因③:KVヘッド数の違い (GQAの効率)
- LLM-JP-4はKVヘッド数が 8 (n_head_kv = 8) ですが、Gemma-4は 2 (n_head_kv = 2) です。
GQA(Grouped Query Attention)という技術において、KVヘッド数が少ないほど、過去の文脈を記憶するメモリサイズ自体が小さくなります。
アーキテクチャの違いはパフォーマンスによくあらわれる
こうしたことから、アーキテクチャの違いはパフォーマンスによくあらわれるものとして、一定の結果を得ることができました。実際のところ、どうやらLLaMa-2アーキテクチャベースだとおそらくは128kは無理じゃないか?という印象を持つぐらいには出力パフォーマンスはその後急激に落ちていったのは確かですし、長いマルチターン会話、あるいはコード出力のような超々長コンテキストを相手にするような領域では、新しいアーキテクチャへもっていき、より記憶の劣化を防ぐような取り組みをしたほうがよさそうです。
今回はllm-jp-4の中でも小規模モデル8bを試したのですが、上位モデルはQwen-3-MoEをベースにしていますので、また違った挙動が確認できるのだろうと思います。そうしたときに、どういう出力がそれならばできるのか、個人的に試してみたいところです。
また、前回書いた llama.cppにおけるKVキャッシュ量子化について ですが、q4_0量子化モードでKVキャッシュを構成したら、確かに32kあたりを超えたあたりから同じトークンの繰り返し問題が発生して、その後のターンを進めることができなくなりました。
枯れた技術を採用しているモデルに対しては、おとなしくq8_0量子化モードを採用したほうが良いのかもしれないですねー。

コメント