
タイムアウトは大きめに設定を
さて、起動したDifyにとりあえずArxivで拾ったナレッジを取り込みたく操作してみれば「ああ、やっぱあの頃の環境は相当贅沢やったな」ということに気づく。DB処理がことごとくタイムアウトしておる。なので、まずは.envの修正から手掛ける。
SQLALCHEMY_POOL_TIMEOUT=300
デフォルトの設定では30なんだけど、とてもじゃないけどこのマシンが30秒以内にSQL ALCHEMYの処理を完結できるとは思えない。特に遅延があまり考慮されていない印象を受けるので、これに対して遅延時間を少々長めに設定。あとデフォルト4MBのPGSQL向けWORKING_MEMが異様に低い(4MB)なので、少し大きめに設定(64MB)、共有バッファは元から修正していて128MBから1GBにしており、いったんこれで試したところうまく処理が開始できた。
なぜかいきなりクォーターに達するEmbeddingモデルたち
加えて、なぜかAOAI経由でtext-embedding-3-smallを動かすとエラー429が出てレートリミットを超えたため、これまたいろいろプロバイダ試したところ、VertexAIならいけることが分かり、この中のmultilingual-text-embeddingモデルを使用することに。
このマシン、llama.cpp動かすにもたぶん息切れするので、あまり無理はさせられない・・
そしたらやっとこさプロセッシング可能に。
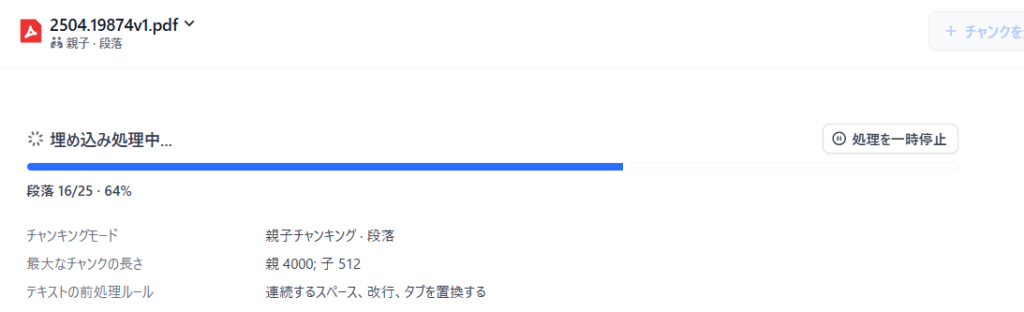
チャンキング→Embedding→PGSQLにストア→Weaviateへ
基本的にまずEmbeddingされる情報は先にPostgreSQLにストアされるのか、チャンキングとEmbeddingをしてる最中は実はそれほどweaviateには負荷がかからない。ただひたすらPlugin_daemonがinvoke処理一筋で頑張り、次々とdb_postgresqlへ送り込んでるようだ。
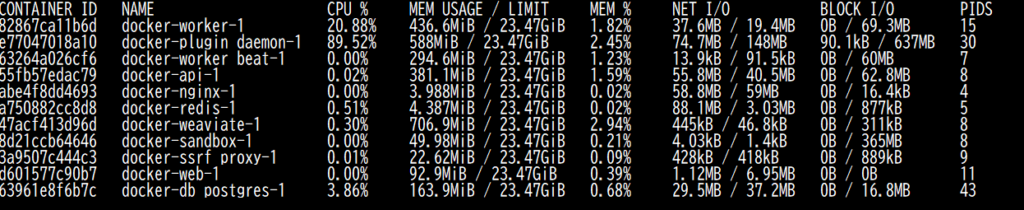
その後、db_postgresにストアしたベクトルデータがweaviateに送られ、使用メモリ量が増大する。このあたりから時々weaviateコンテナのCPU使用率と使用メモリ量が上向いていることが分かる。(706.9MBのメモリ量が、下の図では743.6MBまで増加していることが分かる)
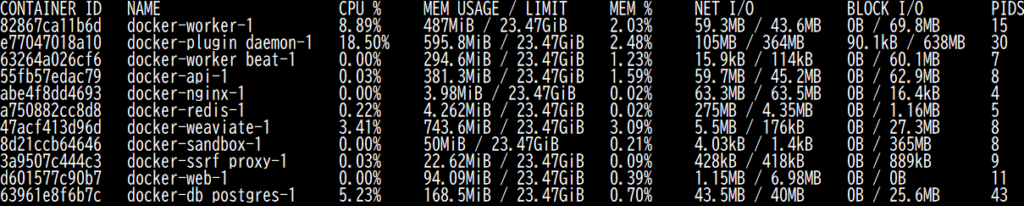
そしてこの処理ループが親チャンク単位で実行され、次々と処理が進んでいき、ついに完了。
「利用可能」の文字列が出たときはほっとしたである。

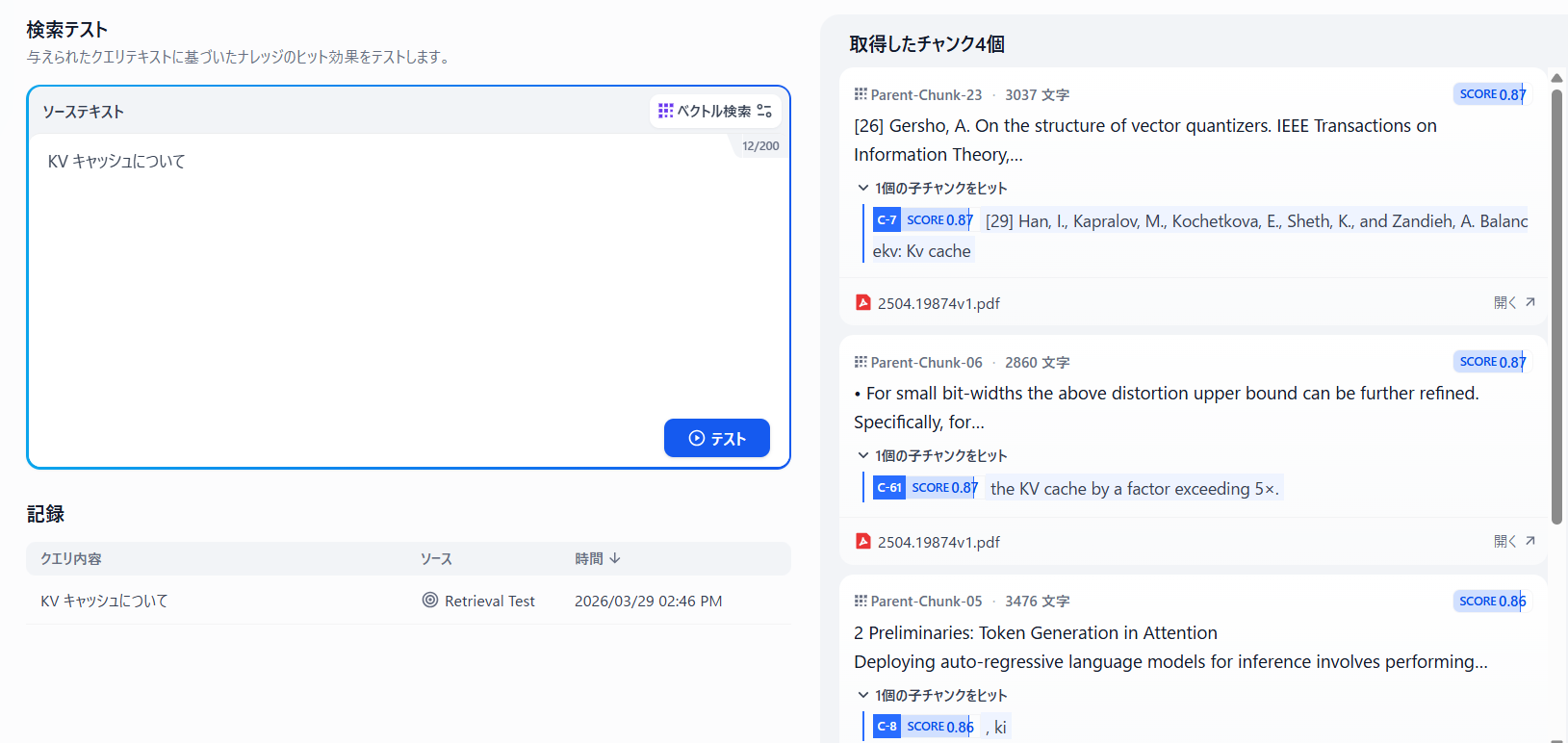
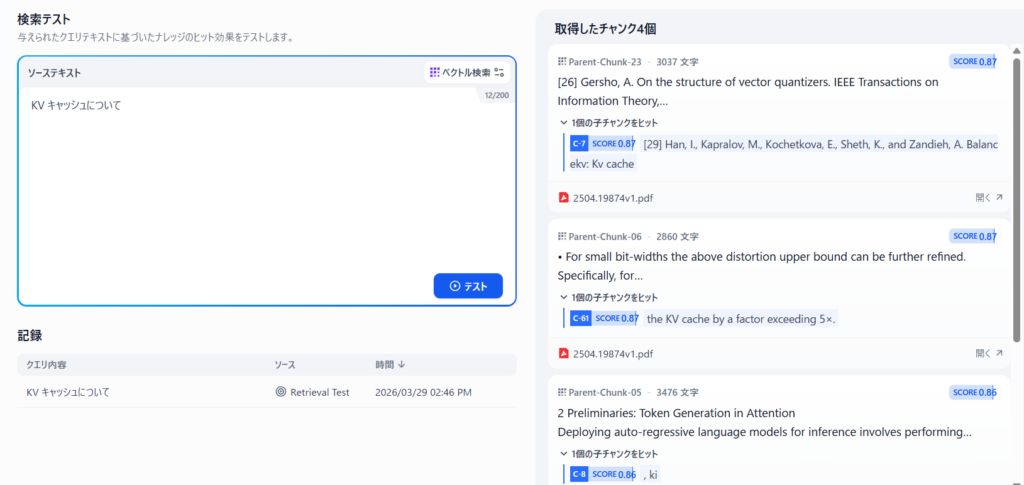
試しにQA処理を実行してみる。ベクトル検索を行うこととし、検索クエリに「KVキャッシュについて」と日本語で質問すると、以下のようにきちんと近傍のワードが拾えていることが分かる。ベクトル検索は言語間のギャップがあまり大きくならないのが助かるよね。
さて、やっとチャットボット的なものは作れそうな気がする。


コメント