 昔取った杵柄
昔取った杵柄 コンテナ内部でsystemctlみたいなことをしたい
以前紹介した GPUSOROBAN ですが、コンテナを払い出すサービスとして紹介をしました。それ故に通常のVMではできることができないポイントなんかあったりします。例えば systemctl が使えません。これを使うためにホスト側でいじる内...
 昔取った杵柄 Artificial Intelligence
昔取った杵柄 Artificial Intelligence 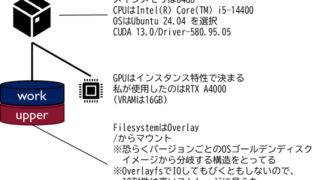 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence  Artificial Intelligence Artificial Intelligence
Artificial Intelligence Artificial Intelligence  Artificial Intelligence
Artificial Intelligence