 Artificial Intelligence
Artificial Intelligence override-tensorで、指定した層だけをCPUにオフロードする手法
うちのブログをご覧になってくださる人からフィードバックが!なかなか書きっぱなしでフィードバックが返ってこない私のこのブログなんですけれども、有難いことにX.comでディープラーニングモデルのことを色々リサーチなさってるきしださん(が当ブログ...
 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence  Hardware
Hardware  Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence 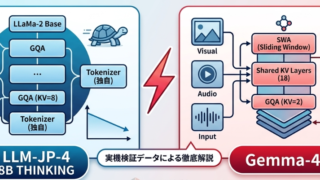 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence 昔取った杵柄
Artificial Intelligence 昔取った杵柄 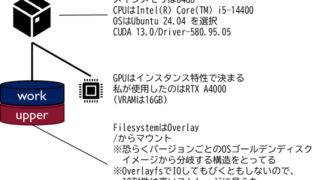 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence