 Artificial Intelligence
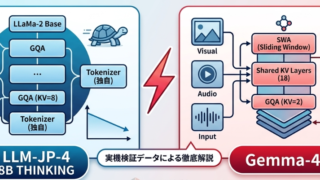
Artificial Intelligence アーキテクチャの違いで何が変わるのか?
アーキテクチャの違いで言語モデルの動きに差が出るのか?というところがなかなかピンとこないことがあります。特にDeepLearningモデルの領域では、ことあるごとに新しい仕組みが生まれては世代が変わり、それが学習の差によって出るものなのか、...
 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence  Artificial Intelligence
Artificial Intelligence