 Artificial Intelligence
Artificial Intelligence Dify/llama.cppの利用は盲目的にはできない件
llama.cppの心得:同時接続数に気を付けようEmbeddingモデルを使う際、私はローカルSLMをよく利用します。理由は「レイテンシーが低いから」の1点に尽きます。API型LLMで実行する場合に比べて恐ろしく処理が速くなるんですね。ま...
 Artificial Intelligence
Artificial Intelligence 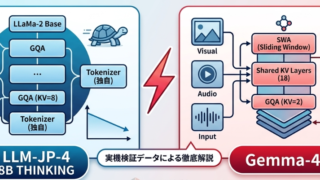 Artificial Intelligence
Artificial Intelligence  Artificial Intelligence Artificial Intelligence
Artificial Intelligence Artificial Intelligence